







«Правильный» robots.txt — это наверное одна из самых заезженных тем в мире SEO-оптимизации сайтов. Во круг нее очень много разных «мифов и легенд», причем некоторые из них 10–15 летней давности, которые не один год ходят кругами среди подавляющего большинства SEO-специалистов. Иногда смотришь на некоторые вот такие «рекомендации» и невольно задумываешься: а читали ли эти люди официальную документацию или специально портят рейтинг своих сайтов?
Данная статья призваны убрать все возможные пробелы и недопонимания, которые могут возникнуть при составлении «правильного робота». Ниже мы рассмотрим базовые принципы работы поисковых систем, поговорим о том, что вообще собой представляет сам файл robots.txt, о том как действительно его правильно настроить согласно официальным рекомендациям поисковиков «Google», «Bing» и «Яндекс», а также упомянем мета-тег Robots с атрибутом Noindex и разберем при чем тут канонические URL?
- Базовые алгоритмы работы поисковых «краулеров»
- Откуда растут лапы поисковых ботов?
- Что ты зверь такой — Robots.txt?
- Синтаксис и правила заполнения Robots.txt
- User-agent
- Disallow
- Allow
- Использование масок и подстановочных знаков
- Sitemap
- Устаревшие директивы и прочие замечания по заполнению Robots.txt
- Мета-тег Robots и директивы Noindex, Nofollow
- Постраничная навигация и атрибут «rel=canonical»
- Правильный robots.txt для WordPress
- Заключение
Базовые алгоритмы работы поисковых «краулеров»

Не смотря на то, что каждый поисковый бот (он же робот) имеет свои особенности и алгоритмы работы, все же общие принципы у них плюс-минус одинаковые. Как минимум весь нижеследующий текст будет справедлив для поисковых ботов Google, Bing и Яндекс (а другие системы для RU-сегмента в принципе и не используются обычно).
Возможно какие-нибудь там китайская Baidu, американская Yahoo или «анонимная» DuckDuckGo имеют иные алгоритмы работы. И если вы по какой-то причине занимаетесь оптимизацией именно под них, рекомендуется самостоятельно найти материалы по данным поисковым системам.
Поисковые роботы постоянно сканируют сеть (Интернет) и добавляют в индекс (в свою базу данных) новые страницы сайтов, которые им удалось обнаружить. Роботы самостоятельно определяют, какие именно сайты и как часто нужно их посещать, а также какое количество страниц следует обойти на каждом из них. При этом всю работу таких роботов можно условно разбить на 3 основных этапа:
- Сканирование. Где происходит поиск и скачивание текста, изображений и прочего общего контента (в том числе и стилей со скриптами) с сайтов в Интернете.
- Индексирование. Где происходит анализ скачанных страниц, содержащих тексты, изображения, видео, различные технические атрибуты, мета-теги, разметку и т.д., с последующим сохранением соответствующей информации о странице в индексе, который представляет собой специальную базу данных. Разумеется у каждого поискового гиганта эта база своя.
- Выдача результатов поиска. Где после ввода пользователем, какого-либо поискового запроса в соответствующем поисковике, система показывает наиболее подходящие (релевантные) результаты в зависимости от множества условий.
Более глубокие алгоритмы работы и особенности каждого поискового бота нас сейчас не интересуют. Но для большего понимания в поведении поисковых роботов, а также настройки и общей сути файла robots.txt, нам все таки необходимо еще чуть более подробнее рассмотреть первый этап, а именно сканирование сайта поисковым ботом.
Этап сканирования заключается в поиске страниц, опубликованных в Интернете. И поскольку как такового их общедоступного реестра не существует (у каждого поискового гиганта своя «база-копилка» с индексами вашего сайта), роботам приходится постоянно искать новые страницы и добавлять их к списку уже известных ему. Т.е. часть страниц робот уже ранее мог посещать. Другие страницы обнаруживаются в процессе сканирования, при переходе с других известных ему страниц (по внутренним и внешним ссылкам например).
Есть варианты и «принудительного» информирования роботов о новой или изменившейся странице. Например, по типу современной команды Index Now* или через другие API. Также допускаются варианты ручного информирования поисковиков по каждой странице вашего сайта через профиль конкретной веб-панели, типа Google Search Console или Яндекс.Вебмастер. В конце-концов можно предоставить поисковикам так называемую карту сайта, т.е. для сканирование файла sitemap.xml.
*Пример отдачи команды Index Now плагином Clearfy Pro:
В общем обнаружив URL-адрес страницы, робот посещает ее (сканирует), чтобы узнать, что на ней опубликовано. Для этого используется очень мощная распределенная вычислительная сеть (у каждого поискового гиганта она своя) в виде множества серверов по всему миру. Причем сегодня, как правило, на базе алгоритмов ИИ (искусственного интеллекта), ведь робот обрабатывает миллиарды страниц в день.
Разумеется сканирование каждого сайта осуществляется в рамках определенного отведенного ему поискового лимита (квоты). Т.к. мощности серверов даже того же Гугла все таки не безграничны.
Сам по себе «робот» — это вполне себе обыкновенная программа, выполняющая сканирование (отправляя специальные запросы на сервер, где хранится ваш сайт). Такой робот называется обычно «веб-краулером» (от англ. «Web crawler») или чуть реже «пауком». Он автоматически определяет, какие сайты сканировать, как часто это нужно делать и какое количество страниц следует выбрать на каждом из них.
Вот пример схематичной иллюстрации, как в общем виде сканирует сайт тот же Яндекс:
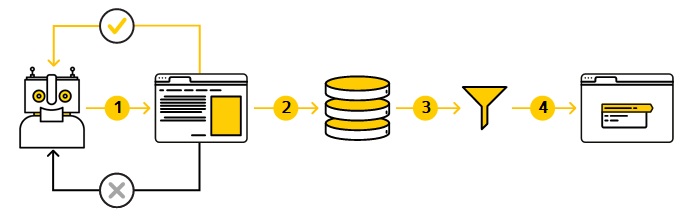
В ходе сканирования робот отрисовывает страницу (текст, картинки) на экране своего виртуального браузера, в том числе с использованием стилей CSS (и это одна из причин НЕ запрещать файлы стилей и скриптов в robots.txt, но об этом позже). Т.е. в каком-то смысле робот имитирует пользователя посещающего сайт, смотря на страницу своими «виртуальными глазами». Хотя в действительности то как воспринимает страницу робот и то, как она отображается в наших браузерах — это все таки немного разные вещи.
Современные краулеры, к сожалению, пока что еще не научились нормально «прокручивать» страницы, кликать на фреймы и скрипт-блоки, отображать эти блоки, распознавать текст на картинках и т.д. Также далеко не все краулеры умеют нормально распознавать блоки обернутые в JS-скрипты.
Все это означает, что чем проще страница с точки зрения HTML кода, тем краулеру проще ее просканировать, а следовательно, и определить что на ней, и в последствии успешно проиндексировать.
Помимо прочего, поисковые роботы сканируют на страницах наличие различных специальных мета-тегов и мета-описаний, директив, микроразметок по типу schema.org, наличие карт сайта, служебных файлов по типу robots.txt и д.р.
По сути, на этом этап сканирования заканчивается. Далее начинается передача в индекс (запись в базу поисковика) нужных сведений о странице, для последующей их выборки поисковой системой на основе запросов пользователей… Но это уже другая история 🙂
Откуда растут лапы поисковых ботов?

Прочитав текст выше, у вас может состояться вполне закономерный вопрос: «А нам то что с этих роботов? Ну пусть себе сканируют, да сканируют дальше, если им так нравится». Но тут не все так просто…
Как уже сказано ранее, краулер выполняет сканирование ВСЕХ страниц сайта. Это его базовое поведение — грести под себя все, что попадается ему под руку, словно маленький паучок желающий поймать каждую муху в свою паутину. Также он делает это постоянно и неустанно в зависимости от частоты появления контента на вашем сайте и некоторых других факторов. В свою очередь это:
Создает нагрузку на сервер, где хранится ваш сайт, т.к. краулер сканирует страницы не при помощи «волшебства и магии», а при помощи вполне стандартных запросов, как бы скачивая поэтапно (постранично) ваш сайт в свой виртуальный пул. Кстати, поэтому если у вас установлен какой-нибудь мониторинг посещаемости/нагрузки на сайт, то сами боты, отображаемые там, для сервера является все теми же пользователями по сути. И если за день страницу посетило к примеру 10 пользователей, половина из них вполне может оказаться просто-напросто все теми же поисковыми роботами.
Отнимает ресурсы самого поискового бота. Хотя сервера того же Гугла очень мощные, но все же не бесконечные по производительности. Все сканирование осуществляется в рамках так называемых квот, которые поисковик выделяет на сканирование каждого сайта.
Может сканировать «лишние» страницы. Далеко не все что есть на нашем сайте роботу положено сканировать и в последствии индексировать. На сайте могут быть технические разделы (допустим «админка» сайта, ядро CMS и т.д.), всякие там формы регистрации, обратной связи, корзина товаров и т.д. А как мы отметили ранее, робот без разбору сканирует все, что попадется ему под руку.
В идеале нам нужно как-то «попросить» поискового бота не сканировать определенные страницы или даже целые части сайта. И такой выход есть. Он появился в 1994 году благодаря консорциуму W3C, разработавшему специальный стандарт, которому следуют с тех пор большинство известных поисковых машин.
Что ты зверь такой — Robots.txt?

Если говорить «по научному», то вышеуказанный стандарт называется — Стандарт исключений для роботов. А представляется он описанием различных директив при помощи текстового файла «robots.txt». Файл этот должен находиться обязательно в корневой директории вашего сайта (на хостингах это каталог, как правило, с названием public_html), в единственном числе и иметь строго одно название — robots.txt.
Cтоит обратить внимание, что файл не обязательно должен существовать физически в корневом каталоге сайта. Некоторые плагины, например по типу Clearfy Pro, могут генерировать его динамически. Т.е. в каталоге с сайтом на хостинге вы можете не обнаружить сам по себе файла robots.txt, но введя в адресную строку URL, например вида https://rocket-koala.ru/robots.txt, сгенерированный файл откроется без проблем.
Файл-роботов используется для (!)частичного управления обходом сайта поисковыми роботами и в ряде случаев, с его помощью также можно исключить контент из результатов поиска. Этот файл состоит из набора инструкций (директив) для поисковых машин, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны (!)сканироваться. В целом, с его помощью вы также можете уменьшить количество запросов, которые поисковые боты отправляют вашему серверу, или запретить сканировать разделы сайта, в которых содержится неважная или повторяющаяся информация.
В предыдущем абзаце ключевые фразы «частичное управление» и «сканирование» — выделены не случайно. Т.к. многие СЕО-шники толи забывают об этом, толи вовсе не знают. Разберем подробнее, что здесь имеется ввиду.
В первом случае подразумевается, что мы РЕКОМЕНДУЕМ поисковому боту выполнять определенные правила из robots.txt. К слову, это описывает и сам стандарт, и является действительностью на практике. То что мы зададим, какие-либо ограничения\разрешения для поискового бота — не гарантирует того, что он всегда будет следовать этой прихоти. Но все же подавляющее большинство ботов будут стараться следовать рекомендациям из этого файла.
Во втором случае подразумевается, что бот (краулер) именно сканирует сайт, а не индексирует его. Это очень важно понимать! Прописав в файле пресловутое Disallow: (сами директивы рассмотрим чуть ниже), мы не закрываем страницу от индексации. Мы именно закрываем ее от СКАНИРОВАНИЯ ботом. А вот уже дальше, что называется по ситуации, робот принимает решение: индексировать страницу, либо нет (и в ряде случаев он все-таки может ее и просканировать и проиндексировать).
Для фактического закрытия от индексации служит другой механизм, описываемый атрибутом noindex мета-тега Robots. Но обо всем по порядку. И начнем мы именно с директив в самом robots.txt.
Синтаксис и правила заполнения Robots.txt

В принципе есть 4 основные директивы (команды\атрибута), которыми достаточно «манипулировать» при заполнении файла робота. Остальные считаются уже устаревшими в реалиях 2024, либо сильно специфическими для определенных, редко используемых ботов (часть этих таких директив, для общего развития повествования, будут перечислены позже).
Основные директивы в robots.txt:
User-agent:тут указывается для какого конкретно бота применяются указанные ниже настройки.Disallow:тут указывается URL путь, относительно корневого каталога сайта, который запрещается сканировать боту.Allow:тут указывается URL путь, относительно корневого каталога сайта, который разрешается сканировать боту.Sitemap:тут указывается полный URL адрес до места, где хранится карта сайта.
Для всех указанных директив общее правило. Название директивы с двоеточием (без пробелов между ними), затем после двоеточия ставится пробел, затем уже прописывается сам параметр.
Прежде чем переходить к детальному рассмотрению каждой из этих директив, хочется напомнить важную вещь. Далеко не каждый бот может одинаково интерпретировать как саму директиву так и ее значение. Как уже упоминалось ранее, те же Google и Яндекс в принципе воспринимают их одинаково. А вот про остальные боты сказать ничего не могу — придется вам изучить тему самостоятельно, если для вас это критично!
User-agent
Тут сильно надолго останавливаться не будем с синтаксисом. Можно указать название конкретного бота для каждой системы, например так:
User-agent: googlebot
# тут параметры для бота Гугла
User-agent: yandexbot
# тут параметры для бота Яндекса
Правда если вы не используете ни специфических директив, ни целенаправленного «прятанья» страниц для конкретных ботов, то в этом нет большого смысла. Достаточно поставить вместо названия бота символ * (звездочка).
Указание символа * — будет означать, что все настройки этой секции будут доступны для каждого сканирующего бота. Этой практики достаточно для 99% любых сайтов. А если вы все таки оптимизируете сайт под конкретную поисковую систему, то тогда можно перечислить все настройки для основных ботов, а потом еще отдельно прописать, какие-то специфические настройки, для конкретного. Например так:
User-agent: *
# тут параметры которые будут действовать для всех ботов: Google, Yandex, Bing и т.д.
User-agent: SuperPuperKrutoyBot
# тут параметры которые будут действовать только для конкретно данного бота
Disallow
Директива Disallow определяет, какие страницы\каталоги\разделы сайта не должны сканироваться поисковым роботом. Вот несколько примеров:
Disallow: /catalog/ # будут закрыты все подкаталоги и фалы внутри директории «catalog»
Disallow: /readme.html # будет закрыт только readme.html в корне сайта
Disallow: /catalog/readme.html # будет закрыт только readme.html, но только внутри директории «catalog»
Несколько важных замечаний:
- Любой путь начинается ОБЯЗАТЕЛЬНО с
/(символ «слеш»), т.е. с корня сайта. Никаких других символов перед ним не должно быть. Это строго регламентируется, например, той же Google документацией! Очень часто в «примерах» на других ресурсах можно встретить в начале пути*(т.е. маска означающая любой символ) и прочую ересь. И хотя современные боты довольно таки умные, т.е. умеют исключать мелкие ошибки из файла-робота, все же лучше стараться писать так, как это требует документация того или иного поисковика. В лучшем случае бот проигнорирует ошибку (т.е. попытается интерпретировать ее в верном ключе на свое усмотрение), в худшем просто-напросто вообще пропустит строку директивы, т.к. сочтет ее полностью ошибочной. - Регистр символов в пути учитывается. Т.е. файл
name.htmlиName.htmlдва абсолютно разных файла! - Имена каталогов нужно отделять
/в конце имени. Т.к. например/catalog/и/catalogэто по сути два разных имени! В первом случае будет запрещено для сканирования именно содержимое директории «catalog» и всех его подкаталогов (т.е./после имени отсечет все что будет внутри этого каталога со всеми уровнями вложений). Во втором случае будет запрещено сканирование вообще любого объекта имя которого начинается на «catalog». Т.е. если указатьDisallow: /catalog, то будут запрещены к сканированию, в том числе, такие пути как:
/catalog/name.html
/catalog123
/catalog.html
/catalog/?p=dog777&cat=true
- Помните, что директива
Disallow:не гарантирует абсолютный запрет обхода сканирования ботом, и уж тем более не гарантирует факт того, что «закрытая» страница не попадет в индекс. И хотя тот же Google, по сути, не может индексировать контент страниц, сканирование которых запрещено в robots.txt, но как минимум он может индексировать URL этих страниц и показывать его в результатах поиска просто без фрагмента (особенно если на эти страницы есть ссылки с других ресурсов в сети или других страниц вашего сайта).
Allow
Директива Allow имеет обратное значение. Т.е. она определяет пути, которые разрешается сканировать поисковым роботам. Разумеется директива не обязательная. Т.е. если вы ее не укажите это не значит, что роботу не не разрешено сканировать сайт. Она нужна, в частности, как исключающее правило относительно директивы Disallow и используется обычно вместе с ней в связке.
Например, вы исключили из сканирования весь каталог и его содержимое, но все же какой-то его подкаталог хотите при этом не исключать. Тогда можно написать так:
Disallow: /catalog/ # закрываем весь каталог и его содержимое
Allow: /catalog/pages/ # но при этом разрешаем сканировать подкаталог «pages»
Все остальные замечания, относящиеся к Disallow, справедливы и для Allow .
Использование масок и подстановочных знаков
По мимо просто указания пути в директивах и «заигрывания» в Disallow-Allows относительно друг друга, можно использовать чуть более сложные конструкции, использую специальные подстановочные знаки.
*обозначает любое (в том числе нулевое) количество вложений (символов).$обозначает строгое окончание текущего URL.
Тем самым мы можем задавать специальные «маски» расширяющие возможности в указании роботам путей сканирования. Разберем несколько примеров:
Disallow: /*name - запрещает к сканированию любой объект начинающийся с любого имени и включающий себя обязательно слово «name», например будут запрещены такие пути как:
/123name # потому что * определяет любое кол-во символов до слова «name»
/catalog/name.html # потому что * определяет любое кол-во символов до слова «name» и нет ограничений на кол-во символов после «name»
/name/catalog/ # потому что * определяет в том числе и указание нулевого кол-ва символов
Если 1 и 3 примеры еще относительно очевидны, то по 2 у вас могли возникнуть наверное вопросы? Действительно, всегда действует правило, что если указанное имя не «обрублено» с конца, то разрешено любое количество символов после него. А вот для «обрубания» уже как раз таки служит символ $ .
Disallow: /*name$ — будет означать любое (в том числе нулевое) кол-во символов перед «name», но вот после имени уже нет. И например файл вида /name.html или /catalog/name.html директива Disallow: уже ПРОПУСТИТ к сканированию.
В очередной раз напоминаю, что все вышесказанное:
- Является «мягкими» ограничениями. И могут быть обойдены роботом на свое усмотрение, при каких-то определённых условиях известных только ему.
- Является, в каком то смысле, частотным ограничением. Т.е. даже при наличии директивы
Disallow:робот все равно рано или поздно может просканировать закрытую область сайта. Действительно, а вдруг там появился какой-то полезный контент, а на него еще и внешние ссылки появились? Просто наличие этой директивы, в отличии от ее отсутствия, дает роботу (как и вашему серверу) «продышаться». Т.е. робот будет сканировать закрытую область сайта, например, не каждые 2–3 дня, а раз в месяц допустим (пример взят с потолка и к действительности не имеет особого отношения, завися в основном от крауленгового «бюджета» сайта, выданного ему поисковиком). Также в своей базе поисковый робот ставит пометку «страница закрыта в robots.txt», значит ее надо реже сканировать и по возможности не индексировать. - Некоторые роботы полностью игнорируют любые директивы, как и сам файл robots.txt по своей природе вообще! Например, суб-роботы по типу Google «Feedfetcher» или Яндекc «YaDirectFetcher», которые скачивают целевые страницы рекламных объявлений. В основном такими «игнорщиками» являются суб-роботы связанные со сбором фидов, рекламы, статистики для Алисы\Кортаны\Гугл-Ассистента и т.д.
- Есть расхожее мнение среди некоторых СЕО-шников, что на фоне вышесказанного можно, тогда не парится и не закрывать сайт от сканирования впринципе. Т.е. предлагается прописать что-то вроде единственной директивы вида
Allow: /— что будет означать разрешено сканировать все и вся в корне сайта, и довериться алгоритмам поисковиков… Тут я с этим категорически НЕ согласен! Аргументы написаны выше, да и сам файл-роботов придуман изначально не для дураков все же. На крайний случай загляните в «роботы» самих поисковых гигантов (напоминаю, что у любого сайта можно посмотреть информацию о роботе по адресу типа http://yandex.ru/robots.txt) и вы увидите, что там директивы есть и их не мало.
Sitemap
Одним из способов «подсказать» поисковым ботам о новых страницах, появляющихся на нашем сайте, является предоставление им специальной карты сайта - Sitemap. Давайте посмотрим на официальную трактовку-определение для карты сайта от Sitemaps.org:
С помощью файла Sitemap веб-мастеры могут сообщать поисковым системам о веб-страницах, которые доступны для сканирования. Файл Sitemap представляет собой XML-файл, в котором перечислены URL-адреса веб-сайта в сочетании с метаданными, связанными с каждым URL-адресом (дата его последнего изменения; частота изменений; его приоритетность на уровне сайта), чтобы поисковые системы могли более грамотно сканировать этот сайт.
Сканеры обычно находят страницы по ссылкам, указанным на сканируемом сайте и на других сайтах. Эта информация, дополненная данными из файлов Sitemap, позволяет сканерам, поддерживающим протокол Sitemap, найти все URL в файле Sitemap и собрать информацию об этих URL с помощью связанных метаданных. Использование протокола Sitemap не является гарантией того, что веб-страницы будут проиндексированы поисковыми системами, это всего лишь дополнительная подсказка для сканеров, которые смогут выполнить более тщательное сканирование Вашего сайта.
Сам по себе стандарт Sitemap поддерживают и Google, и Bing, и Yandex, да и другие поисковики тоже. Поэтому директива Sitemap: является, в каком-то смысле, вполне обязательной в robots.txt.
Прежде чем прописывать путь до карты сайта в саму директиву, у вас как минимум должна быть сама по себе сгенерированная карта сайта в виде файла sitemap.xml. На самом деле собирать и актуализировать его можно что в ручную, что при помощи специальных сервисов, что при помощи определенных плагинов-автогенераторов карты сайта. В последнем случае, для WordPress например, такую возможность предоставляют SEO-плагины по типу Yoast SEO, AIO SEO, Sitemap Generator и еже подобные.
После того, как сгенерировали тем или иным образом sitemap.xml, в директиву Sitemap: прописывается ПОЛНЫЙ URL адрес до карты сайта. Например вида:
Sitemap: https://example.com/sitemap.xml
Здесь стоит обратить внимание на несколько вещей:
- Само по себе расположение карты сайта относительно текущего корня хоста (домена), а также имя карты сайта могут быть вполне произвольными. Т.е. файл sitemap.xml не обязательно должен располагаться в корне сайта, как и не обязательно иметь имя с указанием слова
sitemap(но все же общепринято указывать именно его). - Карта сайта не обязательна может располагаться даже относительно текущего домена вашего сайта! Ну например, ваш текущий домен называется https://news.ru вы можете сослаться в его файле robots.txt на карту сайта, которая лежит в каталоге другого вашего домена, где аккумулированы все карты с других ваших сайтов. Например, по адресу https://blog.ru/sitemap-all-host/sitemap-news.xml. Разумеется при этом внутри самого
sitemap-news.xmlвсе пути должны ссылаться на хост https://news.ru. - Путь до карты сайта директивы
Sitemap:учитывает регистр символов. Напримерsitemap.xmlиSitemap.xml— это два разные файлы.
Устаревшие директивы и прочие замечания по заполнению Robots.txt
Рассмотрим также несколько директив и параметров, которые уже не актуальны, либо редко используются в файле-роботе.
Host — директива ранее указывалась только для Яндекса (для Google же она никогда не была актуальна и не учитывалась вовсе). Она определяла «зеркала» домена, т.е. в ней указывался, как правило, URL адрес основного домена вашего сайта. Но на смену директиве пришел обыкновенный 301-редирект. И с 2018 года в Яндекс официально отказались от использования директивы Host. Т.е. даже если у вас до сих пор эта директива болтается в robots.txt, то в принципе ничего страшного, директива просто будет проигнорирована поисковиком.
Crawl-delay — директива уже давно не поддерживается ни Google, ни Яндексом. Предполагалось, что директива будет уменьшать нагрузку на сервер, когда поисковые роботы слишком часто посещали сайты владельцев. Т.е. в директиву прописывался некий «таймаут» для робота, сообщающий как часто ему следует посещать страницы сайта. С возросшими мощностями серверов поисковиков и усовершенствованными алгоритмами их работы от директивы отказались. К тому «крауленговые бюджеты» сейчас можно задать вручную в веб-мастерах поисковиков, что разумеется будет считаться для них рекомендацией пользователя, а не железным правилом на исполнение!
Clean-param — не сказать, что директива не актуальна или какая-то там сильно устаревшая, просто в действительности она редко используется по своей сути и воспринимается только Яндекс-ботом (Google этот параметр игнорирует). Она предназначена для, так скажем, вычищения «грязных» страниц. Полную справку по данной директиве читайте в справочнике Яндекса.
Комментарии в Robots - стандарт файла-роботов допускает наличие в нем комментариев. Разумеется комментариев не для «роботов», а для людей 🙂 В начале строки пишется символ # и все, что будет следовать за ним в текущей строке, считается комментарием и будет проигнорировано роботами. Хотя это разумеется не обязательный параметр. Комментарии используют обычно, когда у вас ну совсем какой-то огромный robots.txt с кучей параметров и чтобы вам, либо другим разработчикам не запутаться в них, можно отделять основные блоки строками комментариев.
Кириллица в Robots — тут все просто, кириллические символы в файле-роботов запрещены! Вообще, всегда лучше использовать транслитерацию URL адресов страниц, а сам домен регистрировать изначально в латинице. В мире SEO так будет «жить проще, жить веселее» — как говорил один известный товарищ… Но если у вас все-таки используется кириллические адреса домена, то его название можно сконвертировать при помощи, например, какого-либо паникод конвертера и уже сконвертированную версию адреса вставить в необходимую директиву. Так же название самих страниц допускается писать в виде той самой абракадабры типа «%D0%BF%D1%80%D0%B8%D0%B2%D0%B5%D1%82-%D0%BC%D0%B8%D1%80» (кодировка страницы с названием «привет-мир»).
В принципе есть конечно и другие мелкие особенности и нюансы исполнения robots.txt, но за деталями лучше обратиться напрямую к официальной документации интересующего вас поисковика. Вот несколько полезных ссылок:
Официальная документация Google по заполнению роботов, синтаксису, мета-тегам и т.д.
Официальная документация Яндекс с аналогичными вещами, про IndexNow и т.д.
Переведенная документация и особенности Bing поисковика. Навряд ли кто-то целенаправленно оптимизирует сайт под него, но все же общие рекомендации соблюсти стоит, да и они обычно пересекаются с теми же Гугловскими.
Мета-тег Robots и директивы Noindex, Nofollow
Помимо самого файла-роботов поисковые системы поддерживают различные мета-теги на уровне страницы. Речь идет про код вида <meta name=...> в секции <head> конкретной страницы сайта.
Самих по себе видов этих мета-тегов достаточно много в стандарте HTML. В данном случае речь пройдет о специальной конструкции вида <meta name="robots" content="..., ..." /> и поддерживаемых ей значений по типу Index\Noindex или Follow\Nofollow.
Чтобы лучше понять о чем именно идет речь, давайте взглянем на HTML-код любой страницы, например, на непосредственный код одной из моих статей Как настроить PostgreSQL под 1С для «самых маленьких». Зайдя на страницу нажимаем сочетание клавиш Ctrl + U и видим следующее:
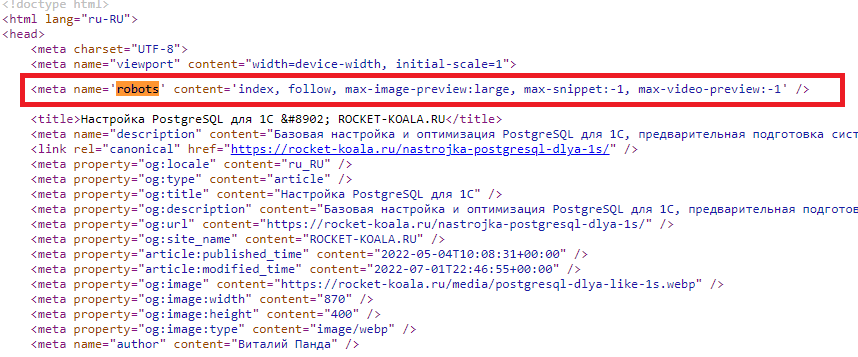
Мета-тег Robots — представляет собой инструкции по сканированию и индексированию страницы, предназначенные для поисковых систем. Этот мета-тег обычно понятен всем поисковым роботам.
Алгоритмы краулеров таковы, что при сканировании сайта они сначала смотрят сам файл robots.txt. Если в нем, в явном виде, конкретная страница не закрыта от сканирования, то далее краулер обращается уже к мета-тегу Robots этой страницы и сканирует значения в нем. А если же в файле-роботов наоборот страница закрыта от сканирования, то краулер будет игнорировать любые директивы секции мета-тега Robots этой страницы!
В нем можно перечислить через запятую несколько значений доступных ему директив. Причем по умолчанию используется значение index и follow — задавать которые в явном виде нет необходимости разумеется. Но нас будут интересовать обратные значения данных директив.
Noindex — директива говорит роботу не показывать страницу, медиаконтент или ресурс в результатах поиска. Если не указать эту директиву, страница, медиаконтент или ресурс будет проиндексирован и сможет показываться в результатах поиска. Т.е. в данном случае принципиальное указание директивы Index — не обязательно.
Внимание! Чтобы директива noindex работала, в файле robots.txt не должен быть заблокирован доступ поискового робота к странице. В противном случае поисковый робот не сможет обработать код страницы и не обнаружит мета-тег noindex. В результате контент с такой страницы по-прежнему будет появляться в результатах поиска, например если на нее ссылаются другие ресурсы.
Кстати, использование noindex это один из способов «удаления» страницы из индекса, если она уже проиндексирована ранее поисковиком.
Nofollow — директива говорит роботу не выполнять переход по ссылкам на данной странице. Если не указать эту директиву, роботы могут использовать ссылки на странице для поиска других целевых страниц. Т.е. в данном случае принципиальное указание директивы Follow — не обязательно. Хотя на самом деле эту директиву лучше использовать в конкретных ссылках на странице, т.е. через ссылочный тег <a hrer=...>, но если действительно нужно запретить переход сразу по всем ссылка перечисленным на странице, то вариант через тег-робот будет вполне уместным.
В конечном итоге пример полного закрытия страницы от индексации будет представлен в виде:
<meta name=«robots» content=«noindex, nofollow»>
Другой вопрос который может теперь возникнуть: как именно прописать мета-роботс в код HTML? Ответ прост: вручную, либо при помощи какого-либо специального SEO-плагина, например Yoast SEO в случае с WordPress. Некоторые темы WordPress, наподобие Reboot, также могут по умолчанию генерировать стандартный код типа того, что представлен выше, на скриншоте кода страницы моего сайта.
Постраничная навигация и атрибут «rel=canonical»
Хотя вопрос канонических URL напрямую не относится к теме статьи и скорее предполагает написание отдельного материала, но все же косвенно можно отнести к нашему «правильному» robots.txt.
Постраничная пагинация (или пейджинг) — это вывод каких-либо данных (например товаров в категории интернет-магазина или карточек постов на главной) с разбиением на несколько страниц.

Такие страницы в своем URL имеют, как правило, идентичный адрес, отличающийся лишь идентификатором в конце с номером конкретной страницы. Например, что-то вроде этого:
https://magazin.ru/catalog/noutbuki/?page=2
И все бы ничего, вот только если не предпринять определенных мер, то страницы-пагинации будут дублировать контент, заголовки и мета-теги первой страницы, а поисковые системы, как мы знаем, негативно относятся к дублям на сайте.
Меры эти могут быть совершенно разными, вплоть до «экстремальных» по типу прямого закрытия от индексации через Noindex (что я делать крайне НЕ рекомендую), либо закрытие сканирования через robots.txt.
Как я уже отметил, сейчас мы не станем разбирать почему прямое закрытие пагинации — это не верно. Отмечу лишь, что индексация пагинации способствует сканированию сайта поисковыми роботами и местами даже ускоряет ее. К тому же при полном закрытии пагинации, нарушается естественное распределение ссылочного веса по сайту, что тоже не очень хорошо.
Одним и методов борьбы с дублями пагинации является атрибут rel="canonical" тега <link>. Есть и другие методы, по типу указания атрибутов rel="next" и rel="prev" тега <link>, формирование не дублирующих мета-тегов и заголовков Title для каждой страницы навигации и д.р. Но это уже отдельная история 🙂
Суть метода «каноникализации» заключается в том, что в качестве канонического (основного) адреса необходимо указывать первую страницу. В поиске будет участвовать только она, но остальные страницы будут посещаться поисковым роботом, с которых он переходит на страницы товаров. При этом их ссылочный вес «слипнется» с первой страницей.
Даже тут отмечу, что этот метод может быть не всегда на 100% уместным, но это гораздо лучше, чем вовсе закрывать пагинацию, например в robots.txt или через Noindex. И единственное, что стоит закрывать в действительности — это если пагинация участвует сразу вместе с сортировками или фильтрами в URL. Хотя это уже решается изначально правильной настройкой и оптимизацией URL с фильтрации карточек товаров например.
Правильный robots.txt для WordPress

Вот и подошли к вопросу, ради которого наверняка многие здесь и собрались 🙂 А именно «Что конкретно прописывать все таки в robots.txt и какие страницы закрывать»?
Тут я вас не много разочарую. Универсальных шаблонов вам никто не даст. Их просто нет в природе — кто бы вам что не заявлял. Все зависит от конкретной CMS которую вы используете, специфики сайта, шаблона, плагинов которые вы навесили на сайт и т.д.
Если брать конкретно WordPress, то можно лишь в первом приближении дать общие советы. Тут в заветное Disallow можно смело добавлять /cgi-bin/, /wp-admin/ и /wp-includes/.
Если на сайте используется поиск, сортировки и прочие «префиксовые» URL, то закрываем их также через маску, например вида /*? или /*search и т.д. Напоминаю, что конкретные значения зависят от конкретного шаблона сайта. Например, у моей темы Reboot страницы с результатом поиска закрываются именно через /*?.
В каталоге /wp-content/ стоит закрыть все, что НЕ относится напрямую к контенту, т.е. кроме каталогов с медиа, самим шаблоном и стилями со скриптами. Все остальное — каталоги с кэшем, плагинами, логами, апдейтами и т.д. можно закрывать. Как итог:
К закрытию рекомендуются:
- Системные папки сервера, ядро CMS и админская часть сайта
- Дубле-формирующий контент: сортировки, фильтры, UTM-метки, результаты поиска по сайту и прочие URL с параметрами
- Страницы пользовательских сессий, оплат, корзины, динамических URL и т.д.
Обязательно оставляем доступ к:
- Разумеется страницам с основным контентом
- Общему мультимедиа-контенту целевой страницы: картинки, видео, аудио
- Каталогам шаблона сайта и функциональных плагинов формирующих «лицо» страницы
- Служебным файлам, отвечающим за общий рендеринг страницы: CSS, JS, шрифты
На последние два пункта обращаю особое внимание! Если поисковые системы не смогут отрисовать (отрендерить) страницы сайта в том виде, в каком их получает посетитель, это приведёт к ряду проблем.
Например, поисковая система может счесть, что сайт не адаптирован для мобильных устройств, либо если важная часть контента выводится средствами JS например, поисковая система просто не получит к нему доступа.
В ряде случаев вместо контента поисковая система увидит обычную «дырку» или малую часть контента. В индекс такая страница едва ли попадёт, а если и попадёт – высоко ранжироваться не будет. В обоих случаях результатом будут сниженные позиции в поиске или полное их отсутствие: мусор в поисковой выдаче нам не нужен!
Напоминаю, что отдельно открыть стили и скрипты можно, например, через что-то вида:
- Allow: /*.css
- Allow: /wp-content/plugins/*.css
- Allow: /wp-includes/*.js
- И т.д.
Заключение
На вопрос «Как правильно заполнить Robots.txt в 2022» мы с вами вполне ответили. Подведем общие итоги и выдвинем основные тезисы по теме:
- Не бывает «правильного» robots.txt, но есть общие правила и рекомендации его заполнения.
- Файл robots.txt предназначен исключительно для помощи поисковикам в сканирования сайта и НЕ связан напрямую с индексацией страниц.
- Есть множество директив, часть из которых уже устарели в реалиях 2024 года.
- По мимо файла robots.txt есть его «помощники» в лице мета-тега Robots и канонических URL.
- Именно через мета-тег Robots можно полностью закрыть страницу от индексации.
- При помощи канонических URL, например можно бороться с дублями постраничной пагинации.
- Ни в коем случае НЕ нужно закрывать отрисовывающие контент файлы: CSS, JavaScript, картинки, видео.
- Желательно закрывать служебные, технические, дублирующие и прочие страницы не связанные напрямую с информационным контентом страницы.
- Проверить свой robots.txt на наличие ошибок можно при помощи сервисов по типу того, что предлагают сами поисковики, например Яндекс ну или прочих сервисов типа такого.


