







Статей по базовой оптимизации, ускорению и настройке PostgreSQL для 1С довольно полно в сети. Где-то перечислены просто основные параметры конфигурационного файла, где-то полная выкладка по установке, а где-то «тонкая» настройка под высоконагруженные проекты.
Данная статья призвана снять многие вопросы новичков по базовой настройке и оптимизации PostgreSQL для 1С, что называется, вобрав в себя лучшие практики кропотливо собранные сообществом за последние лет 10.
Материал был составлен по актуальным, на момент написания данной статьи, редакциям PostgreSQL (в плоть до 15-ой) на основании множества свободных статей в интернете, часть из которых по ссылкам в конце, а также на основе официальной русскоязычной документации самой команды разработчика PostgresPro (отечественная коммерческая команда разработки, вносящая гигантский вклад в развитие и поддержку PostgreSQL в целом) и статей от самой фирмы 1С с их сайта ИТС. Ну и на основании собственного опыта в процессе эксплуатации — куда же без этого конечно 🙂
Изначально все рекомендации собирались автором данного материала, в свое время, как сборник «дорожных заметок» при участии на одном из проектов в 2019 году (система рассчитанная на 200+ живых пользователей 1С, где осуществлялся переход платформы и всех прикладных решений с 7.7 на 8.3), который успешно функционирует и по сей день. Основная задача была настроить PostgreSQL для 1С так, чтобы она работала как минимум не хуже, чем искоробочная связка 1С с MS SQL. В дальнейшем решил нарастить все эти заметки «мясом» и поделиться в качестве уже полноценного материала с широкой аудиторией в реалиях текущего времени, с текущими особенностями платформы 1С и последних редакций PostgreSQL.
Стоит обратить внимание, что все приведенные ниже рекомендации по настройке PostgreSQL для 1С относятся именно к данной связке и скорее всего при работе с другими приложениями эти параметры не подойдут. По возможности данный материал будет со временем актуализироваться по мере каких-то серьезных изменений как на стороне самой PostgreSQL, так и платформы 1С.
- Есть ли жизнь для 1С-сника после MS SQL?
- Немного про саму СУБД PostgreSQL
- Про разные сборки PostgreSQL для 1С
- Рекомендации по выбору ОС
- Общие настройки системы для совместной работы PostgreSQL и 1С
- Про дисковую подсистему СУБД
- Настройка и оптимизация файла «postgresql.conf» для 1С
- Основные параметры подключения 1С к серверу PostgreSQL
- Еще некоторые важные параметры для связки PostgreSQL и 1С
- Настройки AUTOVACUUM
- Подключаемые модули от PostgresPro полезные для 1С
- Основные настройки подсистемы памяти PostgreSQL
- Параметры WAL (журнала предзаписи Postgres)
- Параметры планировщика запросов
- Прочие важные параметры для PostgreSQL и 1С
- Вынесение WAL и статистики в отдельную область
- pg_stat_tmp
- Журнал WAL
- Про регламентные операции по обслуживанию PostgreSQL в связке с 1С
- Про Vacuum и Analyze
- Про Freeze
- Про Reindex
- Итог по регламентным операциям
- Не много «экзотики» для высоконагруженных баз
- Дополнительные полезные ссылки по PostgreSQL
Есть ли жизнь для 1С-сника после MS SQL?

Oracle — был слишком дорог и монструозен для развертывания в типовых «ларьках» (речь про предприятия малого и среднего бизнеса, рост которых был максимально бурным в конце 90\начале 00‑х, и на которых изначально и опирался вендор, продвигая свои бухгалтерские продукты).
IBM DB2 — толком-то в глаза никто и не видел тогда. Хотя по слухам, сама по себе СУБД то весьма не плохая, но вот не пошла в мир…
PostgreSQL - для 1С вообще считалась смехотворным «поделием для гиков», которые любят кодить «в этих ваших Линуксах». Так и получилось, что СУБД от Microsoft была своего рода монополистом и отдушиной в мире 1С.
Забавно, что и сами разработчики платформы, изначально при ее проектировании, руководствовались архитектурными особенностями именно MS SQL и основной упор в дальнейшей поддержке, как не трудно догадаться, делали именно на нее. А остальные три заявленных СУБД были приделаны при помощи ряда «костылей», которые также вендору пришлось реализовывать в своей платформе. Ну а на любые тех. вопросы и негодования пользователей поддержка всегда отвечала , что «да да, поправим лет через 10, ну вот есть MS SQL переходите на него».
Но все же ситуация кардинально изменилась примерно в 2015–2016 году, когда свое второе перерождение для платформы получила СУБД PostgreSQL, не в последнюю очередь благодаря вендору 1С, а также некоторым внешним условиям, в частности веяниям «импортозамещения» в нашей стране. Но обо всем по порядку.
Немного про саму СУБД PostgreSQL
Сама по себе PostgreSQL свободно распространяемая СУБД, имеющая как готовые дистрибутивы для всех современных ОС (Windows, Linux, BSD-семества и прочее), так и открытые исходные коды для самостоятельной сборки. Это позволило создать на ее базе кучу различных «форков», а также адаптированных версий под различные приложения разных вендоров. Разумеется и платформа «1С:Предприятие 8» таким исключением не стала.
Где-то примерно году в 2015 фирма 1С и команда PostgresPro объявили о содружестве, а также некой частичной взаимной адаптации своих поограммных решений. И, например, выросший в этом же году официальный облачный сервис 1С-Fresh, от самого вендора, в своей основе построен именно на базе Постгреса.
В целом же, как сама платформа «1С:Предприятие 8» (начиная примерно с версии 8.3.10), так и основные тиражные решения (по крайней мере локальные версии тех, что представлены во Фреше) довольно неплохо оптимизированы под современные версии PostgreSQL.
Правда все вышесказанной с оглядкой на правильную базовую настройку PostgreSQL для 1С, а также необходимостью (в частном порядке) «тонкой» настройки запросов самого прикладного решения (конфигураций 1С) при действительно высоконагруженных базах в среднем от 1000+ пользователей (что справедливо и для MS SQL на самом деле тоже).
При наличии высоконагруженных (особенно «самописных» или сильно переписанных типовых) баз 1С, при переходе на PostgreSQL с MS SQL, будьте готовы вложить ресурсы (время, деньги, разработчиков) на доведение работы системы до приемлемого уровня, особенно в критичных местах для бизнеса. Да и вообще ВСЕГДА будьте готовы к тому, что потребуется оптимизация запросов под целевую СУБД (любую), а в некоторых случаях даже под конкретную версию этой СУБД. Будьте готовы к проведение предварительного нагрузочного тестирования и некоторым типовым «граблям» самих конфигураций 1С.
Про разные сборки PostgreSQL для 1С

Далее по тексту, чтобы не возникало путаницы в названиях этих разных сборок PostgreSQL будем их для краткости называть соответственно: 1С-ная сборка и PGPRO-ная сборка (причем прошу заметить, речь именно про БЕСПЛАТНУЮ сборку от команды PostgresPro заточенную под 1С, т.к. у команды есть и отдельные коммерческие (читай платные) версии своих продуктов — это продукты «Postgres Pro» и «Postgres Enterpise» — которые в целом также совместимы с 1С платформой) .
Ниже собрал сводную выдержку про все эти версии PostgreSQL, что бы у читателя прояснилась цельная картина:
Ванильная версия — это свободный оригинальный «забугорный» Постгрес не совместимый по умолчанию с платформой 1С (и даже не знает про нее).
1С-ная сборка PostgreSQL — свободный дистрибутив от самого вендора 1С, где берут ванильную версию, подключают в ней ряд своих 1С-патчей, чтобы сборка могла работать с платформой, а также чутка меняют дефолтные настройки конф-файла для этих же целей. Сборку можно скачать с сайта релизов 1С.
PGPRO-ная сборка PostgreSQL под 1С — свободный дистрибутив от отечественной команды разработчиков PostgresPro, где также берут ванильную версию, подключают в ней ряд 1С-совместимых патчей, а также по умолчанию включают еще парочку своих модулей (кочевавших из своего же старшего продукта Postgres Pro), также чутка меняют дефолтные настройки конф-файла для этих же целей. Сборку можно скачать с их официального репозитория.
Продукт Postgres Pro — отдельная коммерческая сборка PostgreSQL, имеет ряд доработок, модулей и т.д. существенно расширяющие возможности СУБД. Также совместима с 1С из коробки. Можно скачать с их официального репозитория напрямую. Но имейте ввиду: продукт доступен бесплатно только для целей ознакомления\тестирования\разработки. Для использования в живом продакшене — нужно покупать. Позиционируется разработчиками, как полный коммерческий аналог продуктам «MS SQL SERVER STANDARD».
Продукт Postgres Enterpise — отдельная коммерческая сборка PostgreSQL. Является их флагманским продуктом, имеет еще ряд более расширенных возможностей в сравнении с версией «Postgres Pro». Также совместим с 1С из коробки. Скачать как-либо напрямую нельзя, хотя вроде как могут дать предварительно пощупать по запросу через их отдел продаж. Для продакшена — само собой платная. Позиционируется разработчиками, как полный коммерческий аналог продукту «MS SQL SERVER ENTERPRISE».
Отличий с точки зрения стабильности, скорости работы и т.д. между 1С-ной и PGPRO-ной сборками не замечено, т.к. исходный код разумеется один. Отличаются, разве что модели распространения дистрибутивов, да некоторые дефолтных параметров конфигурационного файла, а также подключаемые по умолчанию модули.
В случае 1С-ной сборки — установочные дистрибутивы, для скачивания с их официального сайта, доступны только при наличии договора ИТС. По сути, у вас должен быть как минимум действующий договор сопровождения с любой из 1С-Франчайзи, а также регистрационные данные от сайта releases.1c.ru; лишь в таком случае вы сможете скачать их дистрибутив-сборку PostgreSQL.
В свою очередь PGPRO-ный дистрибутив для 1С распространяется без каких-то особых условий (по крайней мере на текущий момент так). Т.е. для получения дистрибутива достаточно заполнить регистрационную форму и получить ссылку для скачивания, либо вообще напрямую скачать с их официального репозитория версию для своей ОС.
По сути, это их бесплатная версия специально заточенная под платформу 1С (так сказать подарок пользователям на фоне сотрудничества с вендором 1С). В свою очередь эта версия является «выпиленной» версией из их основного коммерческого продукта Postgres Pro (например из нее в бесплатную версию кочевали такие полезные модули, которые положительно сказываются и при работе с платформой 1С, как online_analyze и plantuner).
К слову, у них из репозитория можно также свободно скачать и установить полнофункциональные дистрибутивы Pro-версии, которые разрешается использовать для целей изучения и тестирования, а уже при переводе баз в полноценный продакшен приобрести лицензию как полагается. Такой приятный подход можно встретить сегодня далеко не в каждом коммерческом продукте к сожалению…
Субъективно хочется отметить, что все же лучше ставить именно PGPRO-ную сборку для 1С. Как показала практика, в ней встречается меньше «глюков» в сторонних компонентах, а также чуть больше полезной “мелочевки” по сравнению с «1С-ной» сборкой.
Например, чуть более оптимальные дефолтные параметры конф-файла (банально подключены и прописаны по умолчанию модули online_analyze и plantuner, а также некоторые другие настройки), в установщике под Windows чуть больше деталей для установки (например, сам предлагает на основании анализа вашей системы задать более оптимальные параметры для подсистемы памяти) и другое.
Это разумеется не отменяет того факта, что все вышеперечисленное можно настроить и для «1С-ной» сборки. Просто как сам вывод того, что дистрибутивы от PostgresPro, ИМХО, собраны с большей любовью что-ли 🙂 Да и к тому же в их репозитории гораздо больше готовых сборок под разные ОС, а не просто пара RPM и DEB пакетов как на сайте релизов 1С. Ну а в целом, как говорится: «на вкус и цвет…»
Рекомендации по выбору ОС

Из-за особенности самой архитектуры PostgreSQL, изначально рассчитанной для Unix-подобных систем, база данных приложения состоит из огромного количества мелких бинарных файлов, разбросанным по разным подкаталогам (кстати многие ругают Постгрес за такой формат хранения). В отличие от MS SQL, где почти вся БД хранится по умолчанию в одном файле-контейнере с расширением *.mdf (понятно, что есть еще всякие TempDB, журналы транзакций, и саму базу можно разбить при желании на несколько mdf-файлов, но в данном контексте это не суть важно).
По большому счету в базе PostgreSQL каждая таблица или индекс = отдельный файл на диске. Что спокойно может быть 50к+ файлов даже для одной стандартной базы типа 1С:ERP. И вся загвоздка в том, что файловая система Windows (ни NTFS, ни их новомодная ReFS) просто-напросто не способна переварить такое гигантское количество файлов при большом количестве соединений (т.к. могут начаться ожидания блокировок чтения\записи на уровне системы).
Также в целом различия во «внутриядерных» механизмах Linux и Windows. Например, банально виртуальный протокол Shared Memory в Windows не много отличается от такового в Linux, в котором он для PostgreSQL считается более «кошерным». Отличия в восприятие системой тех же огромных страниц памяти (при их использовании конечно) — «Huge Pages» в Linux и «Large Pages» в Windows. Работа с распараллеливанием процессов, т.е. вызовами типа fork в Linux и технологией threads в Windows. А также некоторые другие особенности.
Часть этих механизмов хоть и «сэмулировано» для сколько-то нормальной работы при переносе разработчиками версии PostgreSQL под Windows, но все таки для серьезной нагрузки, ИМХО — only Linux.
Стоит подчеркнуть, что это камень в огород скорее Microsoft, нежели в сторону PostgreSQL. Конечно, с выходом новых версий PostgreSQL постоянно появляются улучшения связанные и с оптимизацией под Windows. Также команда PostgresPro в своих коммерческих продуктах, вроде как, даже обошли некоторые из этих ограничений (правда, как говорится в одном известном видео-меме — «Но это не точно…»).
Вывод! Если у вас относительно небольшая контора пользователей до 50, то вопросов нет, можно ставить в принципе и на Windows (но лучше предварительно погоняйте нагрузки различной 1С-ной синтетикой и со стороны Постгреса тем же pgbench и т.д.). Если больше или планируете систему «на вырост», то ваш выбор Linux — без вариантов!
Общие настройки системы для совместной работы PostgreSQL и 1С
Рекомендуется запретить своппинг разделяемой памяти SYSV/posix (на сегодняшний день рекомендация не столь актуальна, особенно для современных ОС, но если у вас какой-нибудь древняя Unix-подобная система, то устанавливаем значение kern.ipc.shm_use_phys=1)
Рекомендуется отключать Energy Saving (режимы энергосбережения процессора) в БИОС‑е материнской платы (пункты отвечающие за данную опцию могут называться, как правило, Energy Efficient, Power Saving или Suspend), а также выбираем в настройках ОС (и в UEFI BIOS если имеется) план электропитания «Высокая производительность». Поскольку в противном случае могут непредсказуемо вырастать задержки ответов БД из-за несвоевременного переключения частот ядер процессора. Вот неплохая статья с более развернутым содержанием по настройке данных параметров (статья написана для MS SQL, но в данном случае полностью подходит и для PostgreSQL).
Процессорные технологии типа HT(SMT) - лучше задействовать. Современные версии как самого Постгреса, так и ОС отлично справляются с данной технологией.
Сетевой канал между сервером 1С и PostgreSQL (если они физически на разном железе) минимум гигабит, но желательно полноценный 10Gbit прямой линк.
Про дисковую подсистему СУБД

Рекомендуется разнести файлы, от которых зависит максимальная производительность СУБД на разные диски (не разделы одного диска, а именно разные физические диски!).
На сегодня, особенно при развертывании новой системы, можно уже вполне забыть про SATA\SAS рейды из обычных HDD. Современные СУБД в принципе уже давно разворачиваются на SSD дисках, да вполне успешно и долго там живут. Речь разумеется про хорошие SSD, а не про дешевые десктопные версии на QLS памяти.
Не стоит в ваш сервер пихать штаны за 40 гривен дешевые диски — если конечно не хотите каждые полгода-год выкидывать их на помойку. Хорошо зарекомендовали себя диски корпоративного уровня, например от Intel. Также уже собрана немалая статистика успешной монотонной работы «десктопной» PRO-линейки дисков от тех же Samsung (серии 870\980 PRO) — но их лучше использовать все таки под «времянку», а сами базы разворачивать на чем то посерьезнее.
Хорошей практикой считается разнесение файлов как минимум между тремя массивами дисков. На условно первом диске можно разместить сам раздел ОС и основные службы. На втором (или RAID из них) расположить базы 1С. А на третий вывести журнал транзакций (т.е. каталог WAL). Статистику же (каталог pg_stat_tmp) вообще лучше вынести в RAM-диск. Причем настоятельно рекомендуется использовать именно NVMe PCI‑E диски. В целом, подробные настройки по разделению данных рассмотрим немного позже в соответствующем разделе.
Стоит обратить внимание, чтобы все SSD диски/контроллеры/ОС поддерживали TRIM. В современных системах и железках TRIM поддерживается по умолчанию, т.е. если покупаете современные диски или накатываете свежую ОС — можете не заморачиваться. Но если установлена какая-то древняя версия ОС или самого контроллера например (как правило до 2010 года выпуска), то нужно обновлять. В противном случае SSD через пару месяцев под хорошей нагрузкой можно смело отправлять на помойку.
Также не забываем про батарейку RAID-контроллера. И в целом сам контроллер должен быть хорошего класса, иначе это ни чем не будет отличаться от «программного» рейда.
Еще вы должны помнить, что по мере заполнения объема SSD фактически линейно падает его производительность, поэтому заранее подбираем такой объем дисков, чтобы занималось в среднем не более 60–70% пространства на них. Если этот лимит превышается, докупаем еще диски большего объема, переконфигурируем рейд. Ни каких «пфью, еще 20Гб свободно, норм…» не должно быть!
Не забываем про охлаждение дисков. Серверная нагрузка 24\7 это вам не десктопный режим эксплуатации всего по 5–6 часов «браузинга» в день. Особенно касается SSD, т.к. физически они гораздо сильнее «раскочегариваются» по сравнению с HDD.
В качестве ФС подойдет любая linux-like совместимая. Вот интересное тестирование показавшее, что с точки зрения производительности, как таковой разницы между ними нет. Также в книге Грегори Смита рекомендуется EXT4, либо XFS. А вообще есть золотое правило — не столь важно что это: ext4, XFS, Btrfs, да хоть ZFS — главное чтобы вы умели ее правильно «готовить».
Какая-то супер тонкая настройка ядра для ФС не требуется как правило. Но общепринятой рекомендацией для журналируемых ФС (EXT4 — в частности) является отключение опции барьера (ставим barrier=0 в файле /etc/fstab).
Все вышесказанное должно помочь «раскрыться» вашей связке PosgreSQL и 1С, что называется — на максимум!
А вообще, кто полностью хочет полностью погрузиться в настройку дисковой подсистемы конкретно для PostgreSQL, то об этом довольно хорошо расписано в статье Ильи Космодемьянского.
Настройка и оптимизация файла «postgresql.conf» для 1С

Основным из главных отличий между PostgreSQL и MS SQL является их подход к настройке системы.
MS SQL (как и многие другие продукты от Microsoft) поставляется в «закрытом» виде. Т.е. нельзя напрямую залезть в конфигурацию ядра для тонкой настройки под вашу систему, а лишь дается возможность задать некоторые основные настройки для СУБД через «админку». Все остальное система делает автоматически на усмотрение встроенных в нее алгоритмов.
PostgreSQL в свою очередь работает через парадигму Unix-подобных систем, т.е. позволяет тонко «приготовить» систему под ваше железо и сценарии использования через, так называемый, конфигурационный файл.
По умолчанию PostgreSQL устанавливается с дефолтными параметрами (которые из коробки сильно занижены, дабы служба могла запуститься даже на «кофемолке») и требует настройки под конкретно вашу конфигурацию сервера (в зависимости от железа, сценариев использования, нагрузки на базу и т.д.). Особенно это актуально именно под связку с 1С, т.к. изначально архитектура платформы была заточена под MS SQL.
На практике нередко встречаются даже весьма крупные конторы, которые перейдя на Постгрес не делают вовсе, либо делают «от балды» настройки конфигурационного файла. А потом в процессе эксплуатации своих баз, столкнувшись с тормозами системы начинают анализировать загруженность железа, «курить» планы запросов и т.д., хотя по факту в 80% случаев проблема решилась бы изначально правильной настройкой СУБД. Об этом и будет весь нижеследующий текст.
Все основные настройки для PostgreSQL производятся в файле «postgresql.conf». По умолчанию этот файл находится в общем каталоге ../data (либо ../main в более старых версиях) с базами. Обычно типовой путь в Linux, например для PGPRO-шной сборки, будет примерно таким:
/var/lib/pgpro/1c-15/data/postgresql.conf
В файле довольно много различных параметров, мы рассмотрим лишь все те, которые максимально влияют на производительность системы. И в частности те, что влияют именно на связку при работе с платформой 1С.
Перед внесением любых изменений в конфигурационный файл, скопируйте его в отдельный каталог, чтобы в случае неверной настройки, если служба сервера перестанет запускаться, можно было бы скопировать настройки обратно.
Рекомендуется после изменения КАЖДОЙ строки с параметром, перезаписывать конфигурационный файл и рестартовать службу сервера PostgreSQL. И если служба не может запуститься, значит задано неверное значение параметра. Такое вполне может случиться, когда допустим забыли поставить, где-нибудь пробел между знаками параметра или тыкнули на лишний символ с клавиатуры. В этом случае можно вернуть значение на то, что было по умолчанию или отредактировать свою ошибку (для этого нам и понадобится ранее сделанная копия файла).
По умолчанию каждая строка с параметрами закомментирована символом «#» в начале. Для того, чтобы задать своё значение конкретного параметра необходимо убрать символ «#» перед соответствующей строкой и поменять само значение (после знака равно) параметра на нужное. При желании с общими правилами по работе с конфигурационным файлом можно ознакомиться в общей доке команды PostgresPro.
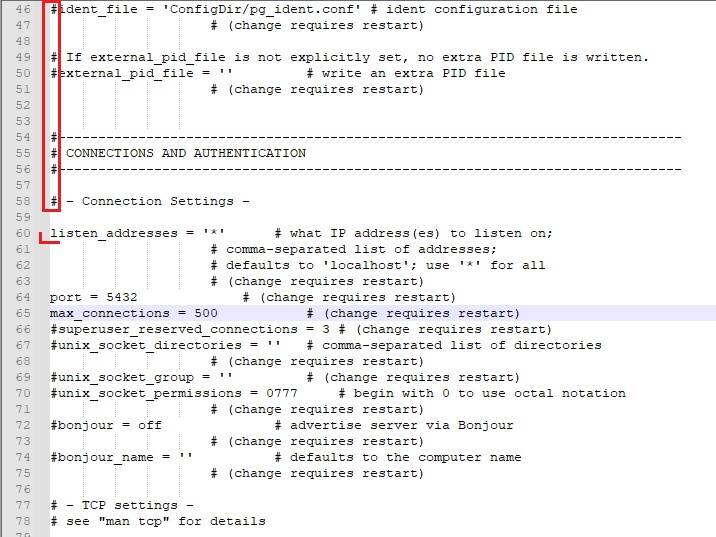
Еще хотелось бы отметить, что сам порядок расположения строк с параметрами в файле не имеет особого значения. Поэтому, при желании, можно их переместить в конец файла, чтобы потом было удобнее работать с изменением этих параметров по необходимости, а не лазить снова по всему файлу в поиске нужной строки.
Также стоит обратить внимание, что, например, в сборке от PostgresPro часть настроек уже вынесена в конец файла, но при этом эти же самые настройки у них почему-то остаются закомментированными и в теле файла. Это я к тому, что будьте внимательны при раскомментировании настроек, чтобы у вас не образовались своеобразные «дубли» с разными значениями. Ищите стандартным поиском по конф-файлу название конкретного параметра; этот параметр в файле должен быть один по итогу!
Дополнительно, чтобы потом наверняка убедиться в том, какое все-таки конкретное значение применено к запущенной службе именно в данный момент, можно обратиться при помощи запроса к системному представлению pg_settings.
Основные параметры подключения 1С к серверу PostgreSQL
Параметры будем разбирать на примере некоторого абстрактного «железного» сервера PostgreSQL (т.е. поднятого на физической машине в единственном числе), которому выделено 128 Гб ОЗУ и 16 процессорных ядер. Будем считать, что служба «Кластера серверов 1С» поднята также на отдельной физической машине и в данном контексте не учитывается. На сервере PostgreSQL развернута некая единственная база — пусть это будет типовая «Комплексная автоматизация, ред. 2.0» объемом ~500Гб, где работают ~200 условных пользователей, со средней интенсивностью запросов в базе. Под ОС, файлы БД и журналы используются быстрые SSD накопители (часть рекомендаций по параметрам в конфигурационном файле будет исходить из данного факта).
В очередной раз напоминаю, что все нижеуказанные параметры мы разбираем в рамках связки PostgreSQL и 1С. Разумеется никто не гарантирует, что указанные значения параметров 100% подойдут конкретно под вашу систему. Но это отличное подспорье, что бы взять эти значения в качестве стартовых, а уже в процессе эксплуатации можете их подкручивать до «идеала».
listen_addresses
Задает адреса TCP/IP, по которым сервер PostgreSQL будет принимать подключения клиентских приложений 1С. Т.е. при необходимости можно перечислить через запятую конкретные IP-адреса которые должны приниматься сервером. Указание по умолчанию символа «*» означает, что будут приниматься все имеющиеся IP интерфейсы в сети. Если сам по себе сервер приложений 1С установлен на отдельной от PostgreSQL машине, то вместо «*» нужно будет указать реальный ip-адрес этой машины. Естественно это далеко не единственный способ аутентификации входящих соединений.
max_connections
Предел одновременных сеансов с базой. При достижении лимита подключение для новых сеансов будет недоступно. Выставлять из расчета реального кол-ва пользователей + небольшой запас в ~50–100 коннектов (для всяких там регламентных\фоновых заданий\зависших сеансов пользователей и т.д.).
Внимание! Крайне не рекомендуется без надобности выставлять большие значения по допуску сессий. Хоть сами 1С и рекомендует в своих статьях устанавливать «не парясь» сразу 1000 или более коннектов, с точки зрения логики работы PostgreSQL это не верно. Каждое подсоединение порождает ещё один процесс postmaster, что естественно требует ресурсов. Плохо написанная программа в цикле открывающая, но не закрывающая за собой соединения, легко создаст проблему.
Например, у нас есть 500 активных сеансов из которых добрая половина это “мертвые” сессии пользователей, которые продолжают съедать полезную нагрузку. Что разумеется не есть хорошо. Это ладно, если у нас настроены таймауты или регламентный перезапуск служб, и они отрабатывают корректно, а вот если нет… На крайний случай если заданного числа по допуску сессий не хватит со временем, просто увеличьте их немного потом в процессе работы.
huge_pages
Использование так называемых «огромных страниц» памяти. HUGE PAGES применяются только в Linux (начиная с 11-версии Postgres стало доступно и в Windows, где они правильно называются Large Pages), для остальных ОС значение параметра будет проигнорировано системой.
Параметр имеет три возможных значения: off — не используются вовсе, on — используются всегда и принудительно, try — используются по усмотрению системы, когда это возможно. По умолчанию стоит «try». В общем случае так и оставляем это значение. При этом значении PostgreSQL использует огромные страницы, когда считает это возможным, а в противном случае переходит к обычным страницам.
Вообще, по умолчанию в Linux используются страницы памяти размером 4КБ, а также и технология HugePages — где страницы бывают 2МБ и 1ГБ соответственно (последнее, вроде как, никто и не использует толком на практике, даже в HightLoad сервисах). Сами по себе настройки связанные с HUGE PAGES задаются через настройки ядра Linux (куда на самом деле лучше не лезть, если вы слабо понимаете, что такое виртуальная память, страницы, буфер ассоциативной трансляции, аллокация в памяти и т.д.).
Есть мнение, что в определенных ситуациях, при очень больших объемах базы и большом количестве активных пользователь, огромные станицы могут положительно сказываться на производительности. При этом важно отметить, что значение «ON» для HUGE PAGES означает принудительное использование огромных страниц ВСЕГДА. И если по запросу системы получить огромные страницы не выйдет — служба PostgreSQL просто-напросто рухнет и не стартанет! Поэтому безопасным значением является все же «try».
Дополнительно, для тех кто хочет разобраться полностью с темой HugePages и в целом про подсистему памяти в Linux, то можно ознакомить в справочнике PostgresPro, а также например в данной статье на Хабре или посмотреть это видео с семинара Яндекс.
ssl
В большинстве случаев сервера защищаются иными способами на уровне системы или через специальное ПО; в данном случае включение шифрования средствами PostgreSQL бессмысленно, к тому же приводит к увеличению загрузки CPU. Поэтому оставляем по умолчанию значение «off».
autovacuum
Один из самых важных механизмов в логике работы PostgreSQL. Параметр autovacuum управляет поведением механизма автоочистки. Он должен быть ВСЕГДА включен для рабочих баз, т.е. иметь значение «on». Можете погуглить, что обычно происходит с БД если параметр поставить в «off». Раньше, на просторах интернета, встречались такие «рекомендации для ускорения» работы сервера PostgreSQL 🙂
fsync
Также еще один очень важный механизм в PostgreSQL. В общем смысле параметр отвечает за целостность БД после возможного сбоя системы (обеспечивает гарантированную запись данных на диск). Если не хотите скоропостижной смерти вашей БД в момент внепланового отключения сервера, то ВСЕГДА оставляем значение «on», даже если вы на 200% уверены в своих ИБП\рейде\файловой системе (даже если она CoW). Перевод параметра в значение «off» можно отнести в золотой стандарт «ТОП вредных советов по ускорению производительности PostgreSQL».
synchronous_commit
А вот тут наоборот. Нужно перевести значение в «off». Тем самым мы выключаем синхронизацию с диском в момент коммита. При этом значительно увеличивается производительность базы. Да, создает риск потери последних нескольких транзакций (в течении 0.5−1 секунды) в случае сбоя, но гарантирует целостность базы данных в целом. Также при этом в цепочке коммитов гарантированно отсутствуют пропуски как таковые.
Вообще параметр определяет, будет ли сервер при фиксации транзакции ждать, пока записи из WAL сохранятся на диске, прежде чем сообщить клиенту об успешном завершении операции. В отличие от fsync, значение «off» для параметра synchronous_commit не угрожает целостности данных: сбой операционной системы или базы данных может привести к потере последних транзакций, считавшихся зафиксированными, но состояние базы данных будет точно таким же, как и в случае штатного прерывания этих транзакций.
Выключение режима synchronous_commit может быть полезной альтернативой отключению fsync, когда производительность важнее, чем надёжная гарантия сохранности каждой транзакции. Значение «on» актуально для БД используемых например в банках, платежных\биржевых системах и т.д., где даже малейшая потеря транзакций чревата последствиями и возможными финансовыми рисками. А вот для баз 1С в общем случае не критично!
max_files_per_process
Максимальное количество открытых файлов на один процесс PostgreSQL. В данном случае «файл» в БД — это как минимум либо индекс, либо таблица, но таблица также может состоять из нескольких файлов.
По умолчанию выставлено значение всего 1000. Если PostgreSQL упирается в этот лимит, он начинает активно открывать/закрывать файлы, что может отрицательно сказываться на производительности в целом. В свою очередь в Unix-подобных системах это обычно даже приводит к ошибкам вида «Too many open files».
Опытным путем выяснено, что для корректной работы 1С стоит увеличить значение по умолчанию хотя бы до 10000 (стандартное рекомендованное значение от 1С — 8000, но можно и существенно больше разумеется). Обратите внимание, что в большинстве ОС это ограничение также может присутствовать на уровне самой системы (ядра).
Например в Linux этот предел нужно не забыть также увеличить в конф-файлах по пути: /etc/security/limits.conf, а также в /etc/sysctl.conf (возможно и еще где-то, читайте мануал по конкретно вашему дистрибутиву Linux). Также диагностировать проблему под Linux можно с помощью команды lsof.
log_line_prefix
Параметр не влияет на работу сервера PostgreSQL, а просто задается для удобства анализа логов. Можно сделать так например: log_line_prefix = ‘PREFIXLOG %m [%d] ‘
Еще некоторые важные параметры для связки PostgreSQL и 1С
Ставим нижеуказанные настройки именно с такими значениями!
bgwriter_delay = 20ms
bgwriter_lru_maxpages = 1000
bgwriter_lru_multiplier = 8.0
commit_delay = 1000
enable_mergejoin = off
row_security = off
standard_conforming_strings = off
escape_string_warning = off
max_locks_per_transaction = 256
Теперь подробная расшифровка этих параметров:
bgwriter_delay — Время «сна» между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в «shared_buffers», с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на «checkpoint» процесс и процессы, обслуживающие сессии (backend’ы). Малое значение приведет к полной загрузке одного из ядер. Рекомендуемое значение от 1С — 20ms.
bgwriter_lru_maxpages и bgwriter_lru_multiplier — Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл «bgwriter» записывает не больше, чем было записано в прошлый цикл, умноженное на «bgwriter_lru_multiplier», но не больше чем «bgwriter_lru_maxpages». Рекомендуемые значения 8.0 и 1000 соответственно.
commit_delay — Параметр добавляет паузу (в микросекундах) перед собственно выполнением сохранения WAL. По умолчанию 0 — т.е. задержка отсутствует. Увеличение задержки может увеличить быстродействие при фиксировании множества транзакций, позволяя зафиксировать большее число транзакций за одну операцию сохранения WAL, если система нагружена достаточно сильно и за заданное время успевают зафиксироваться другие транзакции. Рекомендуемое значение от 1С — 1000.
enable_mergejoin — Включает\отключает (а если быть точнее — увеличивает\уменьшает «стоимость» данной операции относительно других) использование планов соединения слиянием. Отключение полезно для 1С. Подробнее про этот и прочие параметры влияющие на планировщик, хорошо расписано в данной статье.
row_security — Параметр связан с RLS (т.е. Row-Level Security или защита на уровне строк — не путать с «1С-ными» RLS, которые отвечают за ограничения доступа пользователей на уровне записей, обрабатываемых самой платформой 1С). Эта переменная определяет, должна ли выдаваться ошибка при применении политик защиты строк. Со значением «on» политики применяются в обычном режиме. Значение «off» рекомендуется, когда ограничение видимости строк чревато некорректными результатами; например, тот же pg_dump устанавливает именно это значение.
standard_conforming_strings — Разрешение использовать символ \ (обратная косая черта) для экранирования. Этот параметр определяет, будет ли обратная косая черта в обычных строковых константах (‘…’) восприниматься буквально, как того требует стандарт SQL. Если не отключить, платформа 1С не сможет банально запуститься с сервером Постгрес.
escape_string_warning — Включает\отключает предупреждение системы об отключенном параметре standard_conforming_strings. Соответственно отключаем, чтобы система не засорялась лишними сообщениями.
max_locks_per_transaction — Максимальное число блокировок индексов/таблиц в одной транзакции. Стандартная рекомендация от 1С увеличить до 256.
Настройки AUTOVACUUM
Что такое автовакуум, почему настройки именно такие и что каждая их них означает, можно подробнее почитать в статье Антона Дорошкевича
Ставим нижеуказанные настройки примерно с такими значениями:
autovacuum_max_workers = 8
autovacuum_naptime = 20s
autovacuum_vacuum_scale_factor = 0.01
autovacuum_analyze_scale_factor = 0.005
autovacuum_vacuum_cost_delay = 2ms
Примечание! В общем случае, за основу значения параметра autovacuum_max_workers можно взять формулу: количество ядер процессора деленное пополам. Т.к. в нашем примере 16 ядер, то значение равно 8. Можно и увеличить воркеры, главное чтобы хватило work_mem. При увеличении воркеров не забываем увеличить также значение в параметре vacuum_cost_limit. Об этих параметрах подробнее расписано ниже в блоке «Прочие важные параметры».
Подключаемые модули от PostgresPro полезные для 1С
Речь про модули «online_analyze» и «plantuner» за авторством Фёдора Сигаева из команды PostgresPro. По умолчанию могут быть отключены, поэтому нужно проверить, чтобы эти модули были прописаны в окружении «shared_preload_libraries» конфигурационного файла Постгрес.
Модуль «online_analyze» предоставляет набор функций, которые немедленно обновляют статистику в целевых таблицах после операций INSERT, UPDATE, DELETE и SELECT INTO в них. Стоит заметить, что в случае связки с 1С мы будем использовать в параметре «online_analyze.table_type» только значение ‘temporary’. Этой настройкой мы указываем, что анализатор будет включаться только для временных таблиц, в противном случае (т.е. если указать значение ‘all’) могут начаться интересные странности.
Модуль «plantuner» добавляет поддержку указаний для планировщика, позволяющих отключать или подключать определённые индексы при выполнении запроса.
Ставим нижеуказанные настройки именно с такими значениями!
shared_preload_libraries = ‘online_analyze, plantuner’
online_analyze.enable = on
online_analyze.table_type = ‘temporary’
online_analyze.threshold = 50
online_analyze.scale_factor = 0.1
online_analyze.verbose = off
online_analyze.min_interval = 10000
plantuner.fix_empty_table = ‘on’
Основные настройки подсистемы памяти PostgreSQL
Стоит обратить внимание, что все нижеописанные настройки подбираются не только лишь расчетным, но и эмпирическим путем. Т.е. для получения наилучшего результата с производительностью, возможно стоит поиграться с разными значениями этих настроек в продолжительном временном интервале, возможно даже непосредственно на «боевой» базе, анализируя результаты быстродействия системы.
Также не стоит забывать, что фактически все эти параметры имеют «мягкие» пределы и нужны, по сути, для более точного представления планировщика об объемах выделяемой и доступной ему ОЗУ. Т.е. в особых случаях при достижении лимита указанного в параметрах, он может быть без проблем превышен системой на ее усмотрение. Но в тоже время не стоит думать, что параметры можно из за этого ставить как попало или вовсе оставлять со значениями по умолчанию.
Чтобы нижеперечисленные параметры были более наглядными, в каждом из них будут указаны значения (т.е. строка «Прим.:» ) для нашего гипотетического сервера на 20 пользователей.
shared_buffers
Прим.: shared_buffers = 32GB (Общие рекомендации: значение ставится как 25% от общего объема ОЗУ).
Общий буфер сервера для совместного кэша страниц. PostgreSQL не читает данные напрямую с диска и не пишет их сразу на диск. Данные загружаются в общий буфер сервера, находящийся в разделяемой памяти ОЗУ, серверные процессы читают и пишут блоки в этом буфере, а затем уже изменения сбрасываются на диск.
Если процессу нужен доступ к таблице, то он сначала ищет нужные блоки в общем буфере. Если блоки присутствуют, то он может продолжать работу, если нет — делается системный вызов для их загрузки. Т.е. если объем shared_buffers недостаточен для хранения часто используемых рабочих данных, то это приведет к увеличенной нагрузке на процессор, что в свою очередь крайне отрицательно скажется на производительности.
В то же время не следует устанавливать это значение слишком уж большим: это НЕ вся память, которая нужна для работы PostgreSQL, это только размер разделяемой между процессами PostgreSQL памяти, которая нужна для выполнения активных операций. Она должна занимать меньшую часть общей оперативной памяти вашего сервера. Еще один фактор, который следует учитывать — это кэш ОС. При достаточном объеме оперативной памяти Linux будет кэшировать таблицы и индексы в памяти и, в зависимости от настроек, может заставить PostgreSQL поверить в то, что он читает данные с диска, а не из оперативной памяти. Одна и та же страница находится и в буфере PostgreSQL и в кэше ОС, и это одна из причин не делать shared_buffers очень большим. С помощью расширения pg_buffercache можно посмотреть использование кэша в реальном времени. Кроме того, большие значения shared_buffers не так эффективны в той же Windows.
При увеличении shared_buffers обычно требуется соответственно увеличить max_wal_size (об этом параметре ниже), чтобы растянуть процесс записи большого объема новых или измененных данных на более продолжительное время.
Также в некоторых Linux системах могут быть ограничения ядра ОС по выделяемой памяти и ресурсам, т.е. возможно потребуется внести корректировки и в эти параметры.
temp_buffers
Прим.: temp_buffers = 256MB (Общие рекомендации: чтобы временные таблицы в 1с работали нормально, рекомендуется ставить более 128MB).
Буфер под временные объекты, в основном для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии. По умолчанию объем временных буферов составляет восемь мегабайт (1024 буфера). Этот параметр можно изменить в отдельном сеансе, но только до первого обращения к временным таблицам; после этого изменить его значение для текущего сеанса не удастся.
Так как архитектура и логика платформы 1С очень сильно завязана на работе с временными таблицами и при некоторых операциях делает просто гигантское количество записей в эти таблицы, то буфер нужно существенно увеличить по сравнению со значение по умолчанию. Обычно достаточно увеличить этот параметр, где-то до 256 Мб (но не менее 128); значения выше — избыточны.
work_mem
Прим.: work_mem = 128MB (Общие рекомендации: разумные значение в среднем 64MB ~ 256MB).
Лимит памяти на одну операцию типа ORDER BY, DISTINCT, JOIN, и д.р. Внимание! Это НЕ разделяемая память (в отличие от shared_buffers). Work_mem выделяется отдельно на КАЖДУЮ операцию (от одного до нескольких раз за один запрос). В сложных запросах одновременно могут выполняться несколько операций сортировки или хеширования, так что этот объем памяти будет доступен для каждой операции. Кроме того, такие операции могут выполняться одновременно в разных сеансах.
Таким образом, общий объем памяти суммарно всех сессий разумеется может многократно превосходить само значение work_mem указанное в файле; это следует учитывать, выбирая подходящее значение!
По умолчанию стоит четыре мегабайта (4MB), что для 1С слишком мало. Разумное значение параметра определяется следующим образом: количество доступной оперативной памяти (после того, как из общего объема вычли память, требуемую для других приложений, а также shared_buffers) делится на максимальное число одновременных запросов умноженное на среднее число операций в запросе, которые требуют памяти.
Если объем памяти недостаточен (указано слишком маленькое значения параметра) для сортировки некоторого результата, то серверный процесс будет использовать временные файлы. Если же объем памяти слишком велик (указано слишком большое значение параметра, при малом объеме общей доступной ОЗУ), то это может привести к своппингу.
maintenance_work_mem
Прим.: maintenance_work_mem = 1024MB (Общие рекомендации: можно взять значение превосходящее work_mem в несколько раз, обычно достаточно значения в среднем 512MB ~ 1024MB).
Задает максимальный объем памяти для общих операций обслуживания БД, таких как, например VACUUM или CREATE INDEX. По умолчанию значение параметра — 64 мегабайта (64MB). Так как в один момент времени в сеансе может выполняться только одна такая операция и она не всегда запускаются параллельно, это значение вполне может быть гораздо больше work_mem.
Увеличение этого значения может привести к ускорению операций очистки и восстановления БД из копии. Учтите, что когда выполняется непосредственно автоочистка, этот объем может быть выделен в количестве autovacuum_max_workers раз (в нашем примере значение 8, т.е. общий объем на эту операцию может быть выделен до 8Гб), поэтому не стоит устанавливать значение по умолчанию уж слишком большим, особенно при большом количество воркеров, которые мы также задаем в настройках конф-файла.
effective_cache_size
Прим.: effective_cache_size = 90GB (Общие рекомендации: обычно задается как 2\3 (две трети) от общего объема памяти ОЗУ).
Определяет представление планировщика об эффективном размере системного кэша, доступном для одного запроса. Это представление влияет на оценку стоимости использования индекса; чем выше это значение, тем больше вероятность, что будет применяться сканирование по индексу, чем ниже, тем более вероятно, что будет выбрано последовательное сканирование.
Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. При установке этого параметра следует учитывать и объем разделяемых буферов Postgres, и процент дискового кэша ядра, который будут занимать файлы данных Postgres, хотя некоторые данные могут оказаться и там, и там. Кроме того, следует принять во внимание ожидаемое число параллельных запросов к разным таблицам, так как общий размер будет разделяться между ними.
Примечание! Этот параметр не влияет на реальный размер разделяемой памяти, выделяемой Postgres, и не задает размер резервируемого в ядре дискового кэша; он используется только в качестве ориентировочной оценки! При этом система не учитывает, что данные могут оставаться в дисковом кэше от запроса к запросу. Значение этого параметра по умолчанию — 4 гигабайта (4GB), что слишком мало для базового значения.
Параметры WAL (журнала предзаписи Postgres)

Следующие настройки задают параметры WAL (Write Ahead Log — журнал предзаписи), а также позволяют устранить всплески нагрузки на I/O в процессе CHECKPOINT. Предварительно рекомендуется ознакомиться с механизмами WAL и checkpoint и понимать базовые принципы их работы, т.к. это одни из самых важных механизмов в PostgreSQL и в свзяке с 1С, также играют большое значение
checkpoint_timeout
Прим.: checkpoint_timeout = 30min
Максимальное время между автоматическими контрольными точками в WAL. Т.е. этот параметр задает то максимальное время, которое потребуется системе для “самолечения” после сбоя.
Допускаются значения от 30 секунд до одного дня. Значение по умолчанию — пять минут. Увеличение этого параметра может привести к увеличению времени, которое потребуется для восстановления после сбоя, с другой же стороны это поможет существенно снизить нагрузку на дисковую подсистему и уменьшить объем занимаемых данных в процессе записи.
Стоит определить для себя «золотую середину» между этими двумя крайностями в зависимости от требований к отказоустойчивости ваших БД. Для среднестатистической сферической базы, вполне приемлемым значением обычно является 15–30min (но напоминаю, что никто не запрещает указывать любое значение на ваше усмотрение в допустимых диапазонах).
max_wal_size
Прим.: max_wal_size = 8GB
Максимальный размер, до которого может вырастать WAL между автоматическими контрольными точками. Это мягкий предел по сути; реальный размер WAL может превышать max_wal_size при особых обстоятельствах, например, при высокой нагрузке или сбое в archive_command. Значение по умолчанию — 1 ГБ.
min_wal_size
Прим.: min_wal_size = 1GB
Пока WAL занимает на диске меньше этого объема, старые файлы WAL в контрольных точках всегда перезаписываются, а не удаляются. Это позволяет зарезервировать достаточно места для WAL, чтобы справиться с резкими скачками использования WAL, например, при выполнении больших пакетных заданий. Значение по умолчанию — 80 МБ.
Когда старые файлы сегментов оказываются не нужны, они удаляются или перерабатываются (то есть переименовываются, чтобы стать будущими сегментами в нумерованной последовательности). Если вследствие кратковременного скачка интенсивности записи в журнал, предел max_wal_size превышается, ненужные файлы сегментов будут удаляться, пока система не опустится ниже этого предела.
Оставаясь ниже этого предела, система перерабатывает столько файлов WAL, сколько необходимо для покрытия ожидаемой потребности до следующей контрольной точки, и удаляет остальные. Эта оценка базируется на скользящем среднем числа файлов WAL, задействованных в предыдущих циклах контрольных точек. Скользящее среднее увеличивается немедленно, если фактическое использование превышает оценку, так что в нём в некоторой степени накапливается пиковое использование, а не среднее.
Значение min_wal_size ограничивает снизу число файлов WAL, которые будут переработаны для будущего использования; такой объём WAL всегда будет перерабатываться, даже если система простаивает и оценка использования говорит, что нужен совсем небольшой WAL.
checkpoint_completion_target
Прим.: checkpoint_completion_target = 0.9
Задает целевое время для завершения процедуры контрольной точки, как коэффициент для общего времени между контрольными точками. Можно задать значение вплоть до 1.0, но лучше выбрать значение по крайней мере, не больше чем 0.9. По умолчанию это значение равно 0.5. Общая рекомендация от 1С ставить именно 0.9.
wal_sync_method
Прим.: wal_sync_method = fdatasync
Метод, применяемый для принудительного сохранения изменений WAL на диске. Если общий параметр fsync будет отключен (а этого делать крайне НЕ рекомендуется), то параметр wal_sync_method не действует, так как принудительное сохранение изменений WAL не производится вовсе.
Предусмотрена возможность вручную указать один из нескольких предопределенных методов данного параметра. По умолчанию системой выбирается первый из этих методов, который поддерживается текущей операционной системой. Выбираемый по умолчанию вариант, на самом деле, не обязательно будет идеальным; в зависимости от требований к отказоустойчивости и производительности может потребоваться скорректировать выбранное значение или внести другие изменения в конфигурацию вашей системы.
Параметры планировщика запросов
Параметры планировщика дают возможность грубо влиять на планы, выбираемые оптимизатором запросов. Если автоматически выбранный оптимизатором план конкретного запроса оказался неоптимальным, в качестве временного решения можно воспользоваться одним из предопределенных параметров и вынудить планировщик выбрать другой план. Также, улучшить качество планов, выбираемых планировщиком, можно и более подходящими способами, в частности, скорректировать константы стоимости (что мы и будем делать ниже), а также некоторыми другими методами.
seq_page_cost
Прим.: seq_page_cost = 1.0
Задает приблизительную «стоимость» чтения одной страницы с диска, которое выполняется в серии последовательных чтений. Значение по умолчанию равно 1.0; собственно таковое и оставляем.
random_page_cost
Прим.: random_page_cost = 1.3 (Общие рекомендации: 1.1~1.2 для NVME-SSD дисков; 1.3~1.5 для SATA-SSD дисков; 2.0~2.5 для HDD\SAS RAID; 4.0 (по умолчанию) для медленного одиночного HDD диска).
Задает приблизительную «стоимость» чтения одной произвольной страницы с диска. При уменьшении этого значения по отношению к seq_page_cost система начинает предпочитать сканирование по индексу; при увеличении такое сканирование становится более дорогостоящим. Оба эти значения также можно увеличить или уменьшить одновременно, чтобы изменить стоимость операций ввода/вывода по отношению к стоимости процессорных операций, которая определяется следующими параметрами.
Произвольный доступ к механическому дисковому хранилищу обычно гораздо дороже последовательного доступа, более чем в четыре раза. Однако по умолчанию выбран небольшой коэффициент (4.0), в предположении, что большой объем данных при произвольном доступе, например, при чтении индекса, окажется в кэше.
Таким образом, можно считать, что значение по умолчанию моделирует ситуацию, когда произвольный доступ в 40 раз медленнее последовательного, но 90% операций произвольного чтения удовлетворяются из кэша. Если вы считаете, что для вашей рабочей нагрузки процент попаданий не достигает 90%, вы можете увеличить параметр random_page_cost, чтобы он больше соответствовал реальной стоимости произвольного чтения. И напротив, если ваши данные могут полностью поместиться в кэше, например, когда размер базы меньше общего объема памяти сервера, может иметь смысл уменьшить random_page_cost.
С хранилищем, у которого стоимость произвольного чтения не намного выше последовательного, как например, у твердотельных накопителей (SSD диски), так же лучше выбрать меньшее значение random_page_cost.
cpu_operator_cost
Прим.: cpu_operator_cost = 0.0025
Задает приблизительную «стоимость» обработки оператора или функции при выполнении запроса. Значение по умолчанию — 0.0025. Его можно оставить таковым.
Прочие важные параметры для PostgreSQL и 1С


vacuum_cost_limit
Прим.: vacuum_cost_limit = 800
Оценочный параметр, который задается в условных баллах, на основании чего система будет рассчитывать, как часто должен «засыпать» процесс очистки (вакуума). Этот параметр работает в паре с autovacuum_max_workers и многие увеличив первый забывают соответственно увеличить второй.
Общий алгоритм работы примерно следующий: во время выполнения команд VACUUM и ANALYZE система ведет внутренний счетчик, в котором суммирует оцениваемую «стоимость» различных выполняемых операций ввода/вывода. Когда накопленная стоимость превышает предел заданный в vacuum_cost_limit, процесс, выполняющий эту операцию, засыпает на некоторое время (т.е. на значение указанное в vacuum_cost_delay) дабы дать «продохнуть» системе. Затем счетчик сбрасывается и процесс продолжается. По умолчанию значение vacuum_cost_limit = 200.
В целом параметр рассчитывается достаточно просто. Можно брать примерно как 100 баллов на 2 процессорных ядра, т.е. для 16-ти ядерного процессора в нашем примере значение будет 800. Более точная настройка не имеет смысла. Но кому интересен более развернутый алгоритм работы и расчета этих условных баллов, можно ознакомиться со статьей Егора Рогова.
max_parallel_maintenance_workers
Прим.: max_parallel_maintenance_workers = 4
Переменная max_parallel_maintenance_workers появилась начиная с 11 версии PostgreSQL. Задает максимальное число рабочих процессов, которые могут запускаться одной служебной командой CREATE INDEX. В 1С настройка эффективна для монопольных операций, в частности для более быстрой загрузки конфигурации из DT-файла.
Значение можно ставить из расчета: количество ядер процессора\4. В нашем примере 16\4 = 4. Более 6 значение устанавливать не рекомендуется, даже при очень большом количестве ядер!
max_parallel_workers_per_gather
Прим.: max_parallel_workers_per_gather = 0
По умолчанию значение равно 2. Но в случае с PostgreSQL для 1С рекомендуется отключать вообще выполнение параллельных процессов для сборщика, т.е. ставим значение в 0, либо использовать, но с четким пониманием зачем вам это нужно.
Вообще платформа 1С сама по себе не работает по принципу многопоточности запросов (ибо OLTP). Например, есть случай из практики, когда в типовой 1С:ERP при 8 принудительно включенных параллельных процессах расчет этапов производства шел более 6 часов. После же отключения параллельности расчет происходит за 5–7 минуты.
Кстати, отключение этого параметра аналогично рекомендуемому отключению параметра Max degree of parallelism в MS SQL.
JIT-компиляция
Интересный параметр который раньше многие обходили стороной. Если верить данному расследованию — в определенных ситуациях, в частности при сложной структуре RLS, параметрами JIT стоит поиграться. Сам не пробовал, но возьмите на заметку если у вас также есть возникли проблемы в данной части и изучите вопрос отдельно.
Также в 15-ой версии PostgreSQL обновили pg_stat_statements, где теперь можно собирать доп. статистику о работе JIT.
Вынесение WAL и статистики в отдельную область

Как уже отмечалось в общих рекомендациях: каталоги WAL и pg_stat_tmp лучше вынести во вне. Они оба создают не хилую нагрузку на дисковую систему не смотря на то, что могут в целом занимать относительно малый объем. Ниже разберем подробнее.
pg_stat_tmp
pg_stat_tmp — это просто каталог с данными статистики (т.е. критичных данных там не хранится), которая тем не менее не хило так нагружает дисковую подсистему, вследствие постоянной перезаписи (актуализации) данных.
Ходят слухи, что на некоторых HighLoad системах не справляются даже NVMe-SSD накопители и вся система встает «колом». Поэтому лучше сразу вынести статистику в оперативную память.
При внеплановом завершении работы системы и соответственно очистке оперативной памяти с вашими данными базы ничего не случится разумеется. Достаточно будет выполнить команду Analyze и… все на самом деле — статистика пересчитается!
Как правило каталог pg_stat_tmp в среднем занимает считанные мегабайты (30–40Мб), т.е. обычно для рам-диска (в Windows), либо tmpfs (в Linux) достаточно выделить до 512Мб ОЗУ — этого будет более чем за глаза с приличным запасом. В общем случае путь указывается через параметр stats_temp_directory в файле postgresql.conf.
Обычно с подключением рам-диска в Windows особых вопросов возникнуть не должно (инструкций полно в интернете). Рассмотрим на примере tmpfs именно в Linux.
Создаем каталог и задаем права для нашего диска:
mkdir /var/lib/pgsql_stats_tmp # chown postgres:postgres /var/lib/pgsql_stats_tmp
Теперь добавляем в /etc/fstab в самый конец еще одну строку (не забудьте в конце переход на новую строку поставить):
tmpfs /var/lib/pgsql_stats_tmp tmpfs size=512M,uid=postgres,gid=postgres 0 0
Монтируем диск в систему:
mount /var/lib/pgsql_stats_tmp
Теперь идём в наш PostgreSQL конфиг ../data/postgresql.conf и меняем параметр:
stats_temp_directory = ‘/var/lib/pgsql_stats_tmp’
Перезапускаем postgresql:
systemctl restart postgrespro-1c-14
UPD 27.07.2022
В 15-ой редакции PostgreSQL появилась возможность вообще отказаться от файла статистики в привычном виде и переноса его в «темп». Т.е. больше нет параметра stats_temp_directory, статистику больше не надо записывать во временные файлы — сбор статистики перенесен в общую память!
При аккуратном выключении сервера, статистика из общей памяти записывается в каталог pg_stat и продолжает накапливаться после следующего запуска. В случае сбоя сервера, статистика сбрасывается. Здесь всё осталось как и раньше.
Разумеется все это нужно тестировать на реальных базах, но как сам факт нового полезного архитектурного изменения — очень круто!
Журнал WAL
Имеет смысл размещать журналы WAL на другом диске, отличном от того, где находятся основные файлы базы данных. Для этого можно переместить каталог pg_wal в другое место (разумеется, когда сервер остановлен) и создать символическую ссылку из исходного места на перемещённый каталог.
Для WAL важно, чтобы запись в журнал выполнялась до изменений данных в базе. Но этот порядок могут нарушить дисковые устройства, которые ложно сообщают ядру об успешном завершении записи, хотя фактически они только выполнили кеширование данных и пока не сохранили их на диск. Сбой питания в такой ситуации может привести к неисправимому повреждению данных. Администраторы должны убедиться, что диски, где хранятся файлы журналов WAL PostgreSQL, не выдают таких ложных сообщений ядру.
Про регламентные операции по обслуживанию PostgreSQL в связке с 1С

В мире MS SQL есть такое понятие как регламентные периодические операции по обслуживанию БД. В частности — реиндексация, обновление статистики, очистка процедурного кэша и т.д. Запомнилась цитата из статьи Антона Дорошкевича — «..эти операции впитаны с молоком матери в каждого 1С-ника, в каждого админа, у которого нет аллергии на 1С и на 1С-ников. Достаточно запускать их каждую ночь, и будет почти счастье…»
Про Vacuum и Analyze
В отличие от MS SQL наш с вами Постгрес – это версионный тип базы данных. Это значит, что при каждом перепроведении документов прошлого периода, база в 1С засоряется старыми версиями и там нужно периодически наводить порядок. Для этого в PostgreSQL давным-давно есть специальный служебный «пылесос», который как раз «вакуумит» таблицу – называется он AutoVacuum.
Также в PostgreSQL есть AutoAnalyze – что-то типа «апдейтера» статистики (его аналог в MS SQL – это AUTO_UPDATE_STATISTICS). И если в MS SQL эти механизмы мы просто включаем и они работают (на усмотрение встроенных в нее алгоритмов), то в PostgreSQL их можно «подкрутить» и научиться «готовить».
Собственно AutoVacuum – мы уже «приготовили» в предыдущем разделе с настройками конф-файла. AutoVacuum должен быть готов всегда начинать обрабатывать данные, но желательно, чтобы он не делал этого постоянно – его надо «кормить» маленькими порциями. Дак вот мы, в предыдещем разделе, настроили, так скажем, агрессивность поведения механизма автовакуума на оптимально-приемлемое значение для 1С.
Еще часто бывает такое, что мы должны специально «подопнуть» наш Vacuum и Analyze.
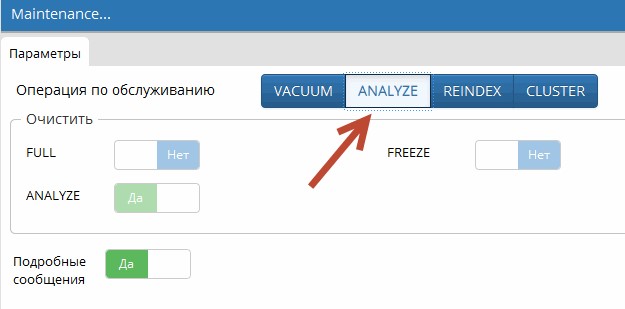
Вот допустим после загрузки DT-файла в пустую базу и при заходе в нее пользователей, первое время может наблюдаться серьезное “подтупливание” системы. Дело в том, что системе необходимо обновить статистику, т.е. мы должны помочь планировщику запросов получить актуальную информацию о таблицах нашей базы. Для этого сразу после загрузки DT, прежде чем запустить пользователей, необходимо выполнить команду Analyze.
Сделать это можно разными способами, например, один из распространенных вариантов – через графический интерфейс pgAdmin.
Про Freeze
Также, на достаточно больших базах ( более 1Tb), настоятельно рекомендуется запускать ночью скрипт Vacuum (без FULL) + Analyze + Freeze (об этой команде чуть ниже). Опять же, можно через pgAdmin, а можно через скрипт командной строки, по типу такого:
vacuumdb -h 127.0.0.1 -p 5432 -U postgres -a -z -F -j 4
Где:
vacuumdb — утилита для выполнения очистки и анализа базы данных
-h 127.0.0.1 — указывает адрес сервера, где запущена служба
-p 5432 — указывает TCP-порт, через который сервер принимает подключения
-U postgres — имя пользователя, под которым производится подключение
-a -z -F — очистить (провакуумить) все базы данных, вычислить статистику для анализатора, агрессивно «заморозить» версии строк
-j 4 — выполнять команды очистки и анализа в параллельном режиме, запуская их одновременно в количестве X
Все остальные возможные значения утилиты можно посмотреть в официальной доке.
Этот скрипт принудительно отвакуумит, проанализирует и заморозит всё необходимые таблицы во всех базах на сервере, причем в 4 потока. И пользователи утром уже зайдут на свеженькую, почищенную и хорошо выдраенную базу, а не будут удивляться почему это у них база работает как черепаха.
Ниже представлено более детальное описание всех этих механизмов включая команду Freeze (заморозка).
VACUUM высвобождает пространство, занимаемое «мёртвыми» кортежами. При обычных операциях PostgreSQL кортежи, удалённые или устаревшие в результате обновления, физически не удаляются из таблицы; они сохраняются в ней, пока не будет выполнена команда VACUUM. Таким образом, периодически необходимо выполнять VACUUM, особенно для часто изменяемых таблиц.
Простая команда VACUUM (без FULL) только высвобождает пространство и делает его доступным для повторного использования. Эта форма команды может работать параллельно с обычными операциями чтения и записи таблицы, так она не требует исключительной блокировки. Однако освобождённое место не возвращается операционной системе (в большинстве случаев); оно просто остаётся доступным для размещения данных этой же таблицы. Она также позволяет задействовать для обработки несколько процессоров. Этот режим называется параллельной очисткой.
VACUUM ANALYZE выполняет очистку (VACUUM), а затем анализ (ANALYZE) всех указанных таблиц. Это удобная комбинация для регулярного обслуживания БД.
VACUUM FULL переписывает всё содержимое таблицы в новый файл на диске, не содержащий ничего лишнего, что позволяет возвратить неиспользованное пространство операционной системе. Эта форма работает намного медленнее и запрашивает блокировку в режиме ACCESS EXCLUSIVE для каждой обрабатываемой таблицы — т.е. требует монопольного доступа к базе. Обычно эту операцию рекомендуется запускать не чаще, чем раз в неделю (например по воскресеньям) или возможно даже реже — активных сеансов в базе при этом быть не должно.
FREEZE выбирает агрессивную «заморозку» кортежей. Агрессивная заморозка всегда выполняется при перезаписи таблицы, поэтому в режиме FULL это указание будет избыточно. Т.е. FREEZE подходит для ежедневной заморозки тяжелых баз с классическим VACUUM ANALYZE.
Возвращаясь к нашей любимой специфике 1С, вспоминаем что у нас данные в базе обычно за 10–15 лет (а многие организации, что такое «свертка» базы даже и в помине не слышали) и работаем мы с последним кварталом как правило. А еще пользователь при этом постоянно жмет «перепровести», а это – минимум данные за месяц, а то и квартал. У нас появляется очень много работы для «вакуума» — почти каждый день.
Чтобы облегчить эту работу – запускайте FREEZE хотя бы раз в неделю (в идеале раз в день) на всей базе. Это неблокирующая операция. Она заставит вакуум пройтись по всей вашей базе, заморозить все таблицы, и все страницы в базе пометятся на «замороженные». Следующий проход автовакуума будет просто мгновенным.
Таким образом, FREEZE помогает всем нашим фоновым процессам отрабатывать быстро. К сожалению, FREEZE – незаслуженно редко используемая функция, которой почти никто в 1С-ном мире не интересуется.
Про Reindex
Помимо «Автовакуума», «Аналайза» и просто «Вакуума с заморозкой», есть еще один важный параметр.Оон есть, к слову, и в MS SQL и в PostgreSQL.
Речь про REINDEX в Постгресе, ну либо INDEX REORGANIZE (бывший DBCC INDEXDEFRAG) в MS SQL.
Вообще, проблема «пухнущих» индексов есть (и есть давно) фактически во всех SQL-like СУБД. В MS SQL, например, эта операция не справляется, когда фрагментация индекса больше 30%. Проводить ее бесполезно – порядок не наведет. Фрагментация так и останется. Правда частично помогает ALTER INDEX REBUILD с операцией WITH ONLINE = ON.
То же самое в PostgreSQL. Команда реиндексации очень часто не справляется с индексами типа Btree, а ведь именно в 1С индексы только и такие 🙂 Т.е. с 1С индексами реиндексация от Постгрес не всегда справляется к сожалению.
Уточним, что значит «не справляется»? Это значит, что индекс — «пухнет». Несмотря на то, что мы все настроили, автовакуум есть (индексы от пустых страничек чистятся). Но индекс «пухнет».
Казалось бы — «ну и пусть пухнет, что такого?» Но не все так просто. Опять же, из-за специфичной работы 1С записей в индексах базы примерно в два раза больше, чем самих непосредственных данных. Если вы разложите любую базу 1С, вы удивитесь, что там примерно 2\3 объема занято индексами. И только 1\3 реальных данных.
В целом для типовых баз в пару сотен гигабайт и до сотни-двух пользователей, проблема может и не так столь остра. В принципе достаточно еженедельного REINDEX и будет счастье. Но для терабайтных баз, где допустим работает уже 500+ пользователей, постоянно вносящих данные в базу – это уже может оказаться проблемой.
Спрашивается «что делать?». Для оптимальной работы PostgreSQL с 1С в этом плане, есть два основных варианта для решения проблемы:
Первый вариант. Начиная с 12-версии PostgreSQL появилась команда REINDEX CONCURRENTLY. Это аналог вышеупомянутого INDEX REBUILD с ONLINE = ON в MS SQL. По сути она одной командой выполняет три строчки кода:
CREATE INDEX CONCURRENTLY new_index ON …;
DROP INDEX CONCURRENTLY old_index;
ALTER INDEX new_index RENAME TO old_index;
С указанием REINDEX CONCURRENTLY произойдет перестроение индекса, не устанавливая никаких блокировок, которые бы предотвращали добавление, изменение или удаление записей в таблице, тогда как по умолчанию операция перестроения индекса блокирует запись в таблице до своего завершения. При переиндексации в неблокирующем режиме есть ряд особенностей, о которых следует знать. Также, для временных таблиц команда REINDEX всегда выполняется более простым, неблокирующим способом, так как они не могут использоваться никакими другими сеансами.
Начиная с 13-версии Постгреса операцию REINDEX немного улучшили, а с 14-версии, судя по описанию, очень хорошо так улучшили. Плюс провели существенные внутренние оптимизации PostgreSQL в целом (в том числе и с Vacuum и др.), что если и не сводит проблемы «пухнущего» индекса на нет, то серьезно улучшает работу в данном направлении. Сами же параллельно выполняющиеся операции REINDEX CONCURRENTLY вообще судя по всему сделали не блокирующими даже друг для друга (до 14 версии такая проблема могла встречаться). Что очень круто на самом деле!
Второй вариант. Использование утилиты pg_repack (собирается из исходников). Самому этой утилитой не доводилось пользоваться конечно, но донести до читателя факт ее существования – необходимо.
Утилита pg_repack – это замена операции VACUUM FULL, которая является блокирующей. Для 1С-ников VACUUM FULL – то же самое, что реструктуризация таблиц, запускаемая из конфигуратора. По сути, наводит полный порядок, правда работать в базе в этот момент нельзя. А pg_repack – это своего рода «Реструктуризация версии 2.0» грубо говоря.
Принцип такой. Рядом создастся таблица, туда аккуратно переедут данные, потом ваша старая таблица заблокируется, в новую таблицу переедет инкремент (то, что успело создастся с момента перепаковки), потом удалится старая таблица и будет переименована новая, чтобы уже с ней дальше работать. Офлайн все равно случится, но буквально на секунду, на две, не больше. Плюс – она наведет порядок в индексах. Именно пересоздав их, как написано выше.
Pg_repack, как и все в PostgreSQL, имеет огромное количество параметров запуска, может перепаковать все таблицы, все базы на кластере, может конкретную таблицу. А может только индексы в этой таблице. В целом судя по всему штука довольно классная, но сложная, изучите материал при необходимости отдельно.
Итог по регламентным операциям
- Если базы типовые, относительно легкие, работает не так много пользователей – настраиваем ежедневный ночной ANALYZE, а также в конце недели монопольно VACUUM FULL + REINDEX (даже если проблемы «пухнущих» индексов нет – делаем – хуже от этой операции все равно не станет). В принципе этого достаточно будет.
- Для более серьезных баз с приличным объемом, кучей пользователей и ОСОБЕННО если есть реальная проблема просадки нагрузки и распухания базы то – настраиваем ежедневный ночной скрипт по запуску Vacuum (без FULL) + Analyze + Freeze. Дополнительно подключаем инструментарий по типу pg_repack, либо операцию REINDEX CONCURRENTLY.
Не много «экзотики» для высоконагруженных баз
Вот статья и фактически подошла к своему логическом финалу. На последок пару моментов, о которых мало кто знает и еще меньше, кто использует на практике. Много текста не будет, просто оставлю для изучения ссылки на «домашку».
Есть такая фича у PostgeSQL, как разделение табличных пространств. Почитайте на досуге в официальной доке что это. С примерами можно ознакомиться, например, в подобной статье. Еще на инфостарте была статейка прям со всеми выкладками, правда удалена, толи автором, толи администрацией (ибо недокументированная фича, публикация которых фирма 1С не очень любит), но кэш Яндекса еще помнит 🙂 Вот еще с этого же портала статейка на аналогичную тему.
Есть еще фича с размещением отдельных таблиц во внешнюю БД на уровне самой платформы 1С (начиная с версии 8.3.20). Правда только для КОРП версии платформы. Но также почитайте на досуге, ибо фича в теории открывает множество возможностей для высоконагруженных проектов.
Далее несколько ссылок на статьи не связанные напрямую с PostgreSQL, а уже с точки зрения «ковыряния» ядра самого Linux. Тут уже реально будет «экзотика и эротика», т.е. для тех, кто любит поработать руками в свободное от работы время 🙂 🙂 🙂
- Про тюнинг памяти в Linux.
- Про настройку ядра Linux.
- Про vm.min_free_kbytes в Linux
Дополнительные полезные ссылки по PostgreSQL
Вместо послесловия, делюсь обещанными полезными ссылками по PostgreSQL:
- Базовая установка PostgreSQL
- Официальные русскоязычные книги от PostgresPro в свободном доступе
- Видео с PGConf.Russia 2020 на youtube: Мастер-класс настройки PostgreSQL для 1С
- Онлайн калькулятор примерного расчета основных параметров postgresql.conf
- Нагрузочный многопоточный тест для теста быстродействия 1С
- Мониторинг производительности и сбор статистики баз PostgreSQL
- Типовые проблемы в PostgreSQL и их устранение
- Про WAL и выявление возможных проблем
- Про балансировщик нагрузки
- Про резервное копирование: тыц1, тыц2, тыц3, тыц4, тыц5, тыц6
- Процедура обновления PostgreSQL с одной редакции на другую
- Регистрация ошибок и протоколирование (настройка логов) работы сервера
- Полезное на ютубе про PostgreSQL в целом: тыц1, тыц2, тыц3
- Как правильно произносить «PostgreSQL» :))



В разделе temp_buffers указаны противоречащие сведения:
… рекомендуется ставить <128MB…
… где-то до 256 Мб (но не менее 128)…
Добрый день, нет противоречий «<128MB» — это значит более 128МВ. Поправил чутка текст в этой части, раз возникло недопонимание)